Heads up – Massive Sports Tech Holiday Deals List is Live!!! The Garmin Fenix 8 is $250 off (even the Fenix 8 Pro is $100 off!), the Apple Watch Ultra 3 is on sale, the Garmin inReach Mini 2 is $249, the GoPro Hero 13 Black, DJI NEO, and a ton of other brands/deals, including Wahoo, Oura, Whoop, Polar, Samsung, Google, and more than 100 sports tech deals here!
It’s been a touch over four months since I first published the Stages Power Meter In-Depth Review. It was interesting to me in that a lot of people took very different things away from the review.
As a result of that review, Stages made a number of updates to their power meter firmware since then, including addressing specific items that were raised as concerns during the review. Based on that, I continued to ride with it. Every single ride for months. They provided iterations of new firmware updates, and I updated. Rinse and repeat.
Except, it wasn’t just riding with a single power meter. No, it was riding with 3-4 power meters concurrently. And 4-7 head units concurrently. One of the Slowtwitch editors recently noted something along the lines of ‘The fun factor of these rides were approximately zero’. Which is pretty true here as well. Aside from being a cold and rainy winter, there’s far more complexity in ensuring that every setting and start/stop time is exactly the same when you have so many head units and power meters running concurrently.
I’m reasonably confident that outside of Stages themselves, I probably have the largest and most complete data set of a single rider against as many additional power meters as one can technically attach to their bike. I do note ‘single rider’ because again – this is just me. It’s not as though they gave me 10 crank arms to test with and assign to random people. And quite frankly, I wouldn’t want that. That’d be a nightmare. And it’d be useless without the same painstakingly strict test protocols that I go through. Protocols that no sane person wants to deal with every.single.ride.
If you’re just finding this page without going to the original review, I encourage you to go to the original review to get a grasp on how the Stages Power Meter works, unboxing shots, and all the usual background information.
A look at the testing methodology:
If there’s anything I’ve learned (or can note to others), it’s just how difficult it is to accurately test power meters. Going out for a ride with two power meters isn’t a test of a power meter. It doesn’t tell you who is right or wrong. It just gives you two power plots. It can tell you and show you potential abnormalities, but not absolutes. It cannot be used to perform a full comparison review. You must have a 3rd unit to provide perspective. Speaking of that 2nd (or 3rd) unit, making the assumption that the Quarq/PowerTap/SRM/Power2Max is always correct is fundamentally flawed. How do you know? What calibration procedures have you done? And have you done them correctly? Even then, as I’ll show you below, it’s easy to make some of those units go askew in certain conditions. Knowing those conditions is critical.
The same goes for data collection. Each head unit records data differently, and finding ones that record data the same way is critical to testing. One of the tools I got added to my bag for these tests was the WASP unit. The WASP allows me to simultaneously collect power meter data from an unlimited number of ANT+ power meters (or other ANT+ accessories) concurrently.
Further, not only does it collect that data concurrently with a timecode, it also collects at a higher rate than a typical Garmin (or other head unit). Normally Garmins will pick one of the 1-8 broadcasts per second, and record that. Whereas the WASP will collect all samples per second and record the average of those.
You can see a screenshot of what this data looks like below:
Which isn’t to say I just used the WASP. Nope, almost all of my rides has between 4 and 7 head units recording concurrently.
This means that every single time I was following a set procedure on how to collect the data, which included:
1) Validation that each power meter was paired to the correctly labeled head unit (validation of ANT+ ID against known PM ANT+ ID)
2) Validation that each power meter did a manual calibration prior to the start of the ride
3) Validation that each head unit was recording at the same settings (1s recording, cadence and power zeros included)
4) Validation that all were using an external speed sensor for indoor rides, and that all circumferences were set identically
5) Starting all head units at exactly the same time (creative use of fingers)
6) After the start of the ride, validate that all sensors were correctly transmitting
7) At approximately 10-15 minutes into the ride, stop by the side of the road and manually calibrate all units
The calibration procedure included stepping off the bike, but over the top tube. Then putting the cranks in the 12/6 position, and then manually calibrating each unit.
Post ride, all of the data would be collected into a single folder and then labeled by power meter and head unit.
While this sounds somewhat simple, doing all seven steps 4-7 times (for each head unit/power meter combination) really adds up.
And that’s all before I even start analyzing the data. Which usually takes hours per ride. There is no application out there today that can cleanly generate all the charts and data plots you see in this review. That’s all done with Excel, painstakingly. A simple 90 minute ride has over 20,000 power meter data points alone to correlate and analyze.
Ultimately though, I have a lot of good data to work with. Clean data, more correctly. There were certainly (many) rides where things went wrong somewhere in steps 1-7, meaning that ride got tossed out. It could be something as simple as the battery dying, or it could be that a unit got inadvertently stopped without me realizing it or that there was some form of ANT+ interference. All of it meant that the ride got tossed from using in this review.
All data shown in this review is prior to the firmware update from approximately two weeks ago. All raw data for this review is available at the end of the review for anyone to download and analyze should they wish.
Some random thoughts before we get started:
Before we dive into the analysis, I want to cover some ground on a few topics briefly. Mostly as a way to ‘catch-up’ folks on various areas of note relevant to this review.
On my pedaling: It’s been funny how some have attempted to identify issues with my riding style during the original review, somehow impacting the tests. Some said I was left-leg heavy (thus impacting things). Some said I was right-leg heavy (more issues). Some said I stopped and started my bicycle the wrong way. Or pedaled the wrong way.
I say this in the nicest possible way: None of that matters. Really, it doesn’t. It’s trying to find fault where fault doesn’t lie. Either the product works with a random cyclist (me), or it doesn’t. Whether it works with a different random cyclist (you), is certainly debatable. I lack the concentration to somehow pedal a certain way for hours on end. Perhaps a professional tour rider does, but for me, I’m just gonna keep on pedaling the same way I have since I had training wheels on. Which based on what I can tell – is probably the same way you pedal. And at the end of the day, it’s all about whether the unit works across the board – yes or no.
On studies of how people peddle: There’s certainly been some interesting studies on how people peddle. I’ve looked at a LOT of studies on this topic. But there’s some key issues that folks like to talk around. First is that most of these studies are 20-30 years old. That doesn’t mean they aren’t useful. But that does call into question the accuracy of the data collection methods on left/right power meters. Keep in mind that it’s last year that we finally got a left/right power meter that works outdoors. Most of the studies are indoor-based, and it’s well proven that power meters act differently indoors than outdoors. Even the more recent ones are very small in their data sets – literally in some cases just a few rides.
Again, I’m not saying to ignore those studies. But I am saying to take them with a boulder-sized grain of salt.
On ‘second/update’ reviews: This is the only time I’ve ever completed a ‘second review’ on a product. Historically when a company prematurely releases a product, they have to live with the reviews published to the internet based on premature release. Ask Motorola how that worked out for the Motoactv. Or Garmin. I often go back and make minor changes or updates based on new features or changed functionality, but not wholesale new reviews. Power meter reviews are actually the most complex reviews I have to publish. They are incredibly tough to get ‘right’, and a lot of data collection and analysis goes into it. Thus, when I publish a second review for a product, that means at least another 2-3 products in The Queue get pushed out further and delayed. That’s the only way it works in a time-constrained system.
On data collection: One aspect that some have wondered whether it impacted the end results was the Edge 510/810 in some of the original tests, which had an issue that resulted in some power drops. Out of curiosity, I looked more closely at this and went and actually ‘nulled’ those drops (they were very predictable timeline-wise in that particular firmware version). However, that still didn’t resolve the core issues brought up in the review around variability. Nulling out the Edge issues only moved things about one half of one percent in most cases (on average it occurred once every 2 minutes). So while it did have an impact, it was sorta like dumping a glass of water into a flooded house.
On differences between power meters: I see a lot of talk about the holy grail of never switching between power meters because it means your data will be offset. That’s true. There’s a fundamental difference in power measurement location between using a crank based power meter and one on a trainer or wheel. No doubt. But I’d argue that in the scope of power meter technology today – it doesn’t matter. I’d argue that most folks don’t calibrate, and even those that do, wouldn’t necessarily know when the data is right or wrong or when a power mis-calibration has occurred. ‘In power meter we trust’. Can you, out on the open road, tell the difference between 5w higher or lower for 4 seconds? How about 10w on an hour long climb? And if you can (which, you might), can you tell me where and when that variation started to occur? And can you do it over the course of multiple years and ensure that ever single ride was calibrated perfectly? And, as you’ll see below – that’s the real question, and not just for the Stages, but for any power meter.
The Tests and Results: Indoor Rides
Let’s dig into a handful of rides. These are rides where all data recording aspects went as planned, thus enabling us to really dig into the data. As with the previous review, any obvious ANT+ transmission errors (i.e. interference) were nulled as to not impact any specific power meter. This is not the same as spikes or drops however, and in the event of those, they were and are specifically called out. ANT+ interference errors are easily seen because they tend to affect all data channels (i.e. heart rate included).
These two rides were done indoors on trainers that have the capacity to both generate resistance as well as measure power. That’s key because it gives us even more data points to work with in some cases (what the resistance ‘should’ be).
90 Minute Indoor Trainer Ride:
This indoor ride was completed on the CompuTrainer (CT), with three additional power meters: The PowerTap, Stages, and Quarq. Per the calibration procedure, each was manually calibrated (or roll down in case of CT) prior to the start of the ride. Then again at the 20 minute marker, all were manually calibrated again. The workout itself was as follows:
A) 10-Minute warm-up
B) Some high-cadence work for 10 minutes
C) (Then Calibration)
D) Building for 15 minutes
E) Then 3 minutes easy
F) 3 x (10 minute intervals with 2 minutes easy in between)
G) 4 x short 30s sprints
H) 5 minute cooldown
With that in mind, let’s look at the overall stacked graph below. This means that the numbers are simply stacked on top of each other. It doesn’t mean that the Quarq is measuring higher. I did this just because for this graph it’s easier to see.
As you can see, the numbers ‘tracked’ quite closely across all units. But as I discussed in the first review, creating a comparative graph isn’t as useful because it tends to ‘skip’ over details, such as the exact variability between units.
Next let’s look at the difference between the power meters in watts. This is somewhat complex to display on a single chart for all units at once, so it’s in multiple charts instead. The titles specify which power meters are being compared. The vertical axis shows wattage, and the vast majority of the ride my average wattage is between 230 and 280w (to give context on percentage).
Note that all charts are sized with a min/max vertical axis of –80w and +80w.
Next is against the CompuTrainer itself. Note that the CompuTrainer has a specified warm-up period of generally between 10 and 20 minutes. Thus why you see the divergence there for those first 20 minutes. It’s not the Stages causing that divergence. Once I complete the secondary calibration on the CompuTrainer, it snaps right into place.
For completeness, here’s the Quarq vs PowerTap numbers. As you can see, any two power meters will differ.
So what do you see above? Well, in all the charts the vast majority of the time you see the difference being less than 20w. You’ll see some spiking towards the end, but that’s in the 500w+ intervals that I was doing, and thus the difference is likely due to lag more than anything else. But remember, we’re not looking at any difference itself as being bad, but rather the variation of the difference. Each power meter measures power in difference places. As a result, the PowerTap will generally show less wattage than the Quarq, for example. So we’re looking to have more of a steady line – wherever that may be (high or low).
In looking closely, you see that in general the variation was lowest when comparing the PowerTap to the Quarq, and the Stages to the CompuTrainer.
But if we step back and look at this graph from the standpoint of a coach, focusing in particular on the three main interval sets – it’s clear that you can easily discern what the athlete is doing, and their output level.
If I look at just the first 10-minute interval for example, here’s the averages:
As you can see, any coach could easily use any of those numbers to give perspective feedback to an athlete on how this ride went. In my case, all three intervals were set to essentially the same values at the start, with a slight fade of 10w over the course of the interval (where I backed off the wattage to keep within a HR zone).
What about one of those sprints at the end? Well, here’s what one of those look like (averages including the build/fade):
As you can see, there’s a bit more variation, but not much. But which one is right? That’s the tough part. How do you quantify exactly which one is correct? The Stages and PowerTap were only 1w apart.
Now let’s look at total ride averages. As noted once before – that’s the absolute easiest bar to meet. I can put up a $99 PowerCal strap and get pretty close to spot-on averages (within a couple watts). But nonetheless, here they are:
We see that the Quarq is the highest, which is logical – it’s measuring power closest to my legs. And the PowerTap and CompuTrainer are lowest, also logical given their place later in the equation (due to drivetrain loss). We see the stages sits below the Quarq, and in this case slightly below the PowerTap as well. For reference, the difference between the Quarq and the Stages is 4%, whereas the Stages and the PowerTap is 1.5%. And the Stages and the CompuTrainer is less than 1%.
80 Minute Indoor Trainer Ride:
Ok, next up, another indoor trainer ride. The structure was fairly similar as the first one:
A) 10-Minute warm-up
B) (Then Calibration)
C) Some high-cadence work for 10 minutes
D) Building for 15 minutes
E) Then 3 minutes easy
F) 3 x (8 minute intervals with 2 minutes easy in between)
G) 4 x short 30s sprints
H) 5 minute cooldown
With that in mind, let’s look at the overall stacked graph below. Again remember that the stacked graph simply shows all of them on top of each other, thus there will naturally be gaps. It’s used to easily see the differences.
So let’s dive into those differences. Like above, I’ve done ‘difference’ charts pitting the Stages up against each one. Here’s the Quarq vs Stages – difference in watts. In order to keep them inline with the earlier charts, the scale was kept at +/-80w. In the below example it bumped just a touch bit higher in those intervals, at 94w.
So before we move onto the others, you’ll see that in general it’s within 20w the entire time. Again remember that delays in transmission and recording can cause some of the variability. The spikes you see at the ending are due to the quick sprints I was doing. Because of the fact that these were only 20 second sprints at a high intensity (500w+), they can easily produce differences like you see due to that delay.
Here’s it plotted against the KICKR (via ANT+):
And then here’s the Quarq and KICKR plotted. Remember all these graphs are smoothed at 10s (the underlying data is).
You’re probably looking at the above and seeing a lot of variability with the KICKR. And that’s true. Remember that the KICKR measures power based on changes to speed. It’s doing it differently than based on pure strain gauges. What you see above is that during the portions of the workout where I’m shifting speed/cadence/power significantly (the high cadence portions & the sprints), we see variability due to data lag. But in the main sets we see the values very close (less than 10 watts).
Here’s the average/max/NP for the ride:
As we can see, the average and NP numbers were very close. The max watts on the KICKR was a bit lower, but that makes sense because it wouldn’t likely have felt a 1s spike during a sprint as high as the Quarq or Stages. And at 753w, the difference between the Quarq and Stages is exactly 2.5%. Well within the published margin of error for either unit.
The Tests and Results: Outdoor Rides
Now we get to the fun stuff – outdoors! While I have lots of rides in Paris, I’m actually using two particular rides below for a reason. First is that I have the WASP data, which makes it easier and cleaner to visualize. But second is that unlike my Paris rides which are full of stops due to traffic/etc, these are more or less nonstop. Thus making it easier to both visualize as well as spot any differences. With stop/starts of traffic, it can become very difficult to separate out drops/spikes from simple stopping and starting rapidly.
Las Vegas Desert Ride:
This was a ride I did while in Las Vegas in mid-April. First up is the stacked graph. Now, this can be really busy looking – because it’s far more variable outside than inside. The route itself is more or less never-ending rollers. So I’m constantly shifting power according to terrain. Note, you can click on any of these to expand a bit.
So, let’s smooth things out a bit with a 10-second average:
Again, remember these are stacked, and thus not the actual difference between the units – but rather the relative differences in how they track.
Now let’s look at the differences between each one. As with before, these are all smoothed at 10s.
Now for the Stages vs PowerTap:
And finally, Quarq vs PowerTap:
Now, the challenge here continues to be the variance in outdoor data when comparing rides side by side. So I applied a 1-minute (60-second) smoothing to it:
So within this, we can clearly see how they tracked. In most cases they aligned quite well. We see that in general the Quarq tends to ‘rise’ above the rest from a max standpoint, either because it’s measuring further up the drivetrain (likely), or because it catches some of the short bursts a bit better. We see that the Stages pretty much just slides in between the Quarq and the PowerTap and tracks well against both. The only cases where we see differentiation seem to come from the PowerTap on some of the descents – reporting a bit lower power than the rest.
Finally, here’s the totals across all three units:
As you can see, all within the same ballpark. But again, getting ride total averages in the same ballpark is pretty easy in the grand scheme of power meters. What I do appreciate though is that you can start to see a pattern between the Stages, Quarq and PowerTap being developed. We see that the Quarq tends to be the highest numbers (Avg/NP), with the Stages slightly below it, and then the PowerTap beyond that. This likely means that my left leg is just a tiny bit weaker than my right leg, as the Stages is only measuring left-leg. The difference between the PowerTap and Quarq makes sense and is inline with expectations, likely due to drivetrain loss.
Mountain Ride:
This ride was done shortly after the Vegas ride. But now I’d travelled to Los Angeles and this ride was starting right at the base of the nearby Angeles National Forest (basically a mountain range), and then heading up into it. The weather down low and on the climb was miserable (pouring rain, cold), but up top it was beautiful.
I really wanted to include this ride because it shows just how massive the impacts of weather and calibration can be on data. Data that unless you had multiple power meters on your bike, you’d likely not realize there was an error.
First up, let’s look at the stacked graph. Quite frankly, this is a mess to try and decipher– so let’s just move on.
So let’s go ahead and apply a 1-minute smoothing to it. This creates a rolling average of the last 60-seconds of data.
Wow, lots of interesting stuff in there. But before we do that, let me give you the elevation profile of the ride that goes along with this. This is set to display as ‘time’, because that’s the same as above (seconds). I specifically moved the elevation points to the right side of the graph, so that it basically aligns visually to what you see above. Where the numbers are on the right side the mountain just goes back down (I start/end in the same place).
What that in mind, what you see is that there was no place for any auto-zero type technologies to kick in on either the Quarq or the PowerTap. In the case of the PowerTap, that happens while coasting. And in the Quarq, when I backpedal. Since I was literally climbing for nearly an hour straight – the only way to do so would have been to stop and get off my bike.
So I did….
First calibration: You’ll see a manual calibration I did (I marked it on the chart two screenshots above), this was about 15 minutes up the hill, where I literally pulled off to the side and manually calibrated. In doing so, all three PM’s started to align again.
But wait, that didn’t last terribly long. Look below. In yellow highlighter I’ve highlighted the two points where I did a calibration or auto-zero. As I continued to climb, you see the power meters start to drift apart. The stages stays relatively constant, but the Quarq drops off significantly – upwards of 50w+. And the PowerTap even starts to drift downwards as well, about 10-15w.
As soon as I pulled over to a random viewpoint and did an auto-zero coast, they both snapped right back in place.
Why were they drifting? Well likely because of this:
This is the temperature chart for my ride. You can see a 15*F+ shift. Keeping in mind that the Edge 800 temperature gauge (which is what this is from) has the updating speed of a turtle. It would literally take 5-10 minutes to drift from 72*F to 0*F in a freezer. So in reality, the temperature shift is likely closer to 20*F+. Here’s what it looked like outside (it’s pouring):
So how do I know that the PowerTap and Quarq were drifting, and that it wasn’t just the Stages? Well, some if it comes from knowing yourself. In my case my heart rate stayed pretty constant across that timespan. And while heart rate isn’t always a great indicator of power, it does help provide context. I certainly wouldn’t have lost 50-70w in wattage over the course of just an hour climb.
Next is that the Stages contains temperature compensation, whereas the Quarq doesn’t. Also, once the auto-zero was done on the Quarq and PowerTap, everything instantly aligned back to where it should have been. Keep in mind there is no manually triggered auto-zero on the Stages (happens continuously), so there was nothing changed there at that time.
We also see some of this same drifting in reverse (plus a bit of other funkiness) happening to the Quarq on the descents on the way back down.
So, as we look at the ride totals, you’re going to see data different than ‘the norm’. Because the Quarq and PowerTap were measuring low during the climb, these numbers will be lower for average and normalized power. Of course, that doesn’t impact max power, which is across the entire ride. In this case, we do see a fair bit of variation in maximum power – more so than I would have expected, with them each offset about 100w (200w range in total). The challenge with max power though is that it can be one split-second packet that determines it.
So where does this leave us? Well, the Stages appears to have a fairly solid temperature compensation system built into it. The PowerTap didn’t drift significantly in comparison to the Quarq, though we certainly saw that.
Now, when we look at the middle portion of the ride where the temperature was fairly constant, we see that all three units tracked very well against each other:
Excluding the climbing/descending aspects, you could have easily used the middle data from any of those power meters. It’s only when you include the climbing/descents that you reduce the viable units to use for this particular cold and rainy day.
Cadence items of note:
I wanted to briefly cover cadence, though I thought it was pretty well covered in the original review. As you may remember, cadence within the Stages Power Meter does not depend on a cadence magnet, and thus uses an internal accelerometer. This means that there is no magnet installation required, nor any other sensor required on your bike. It just does its thing internally to the pod attached to your crank arm.
Now in the original review people seemed to continually look at the graphs and think that I said there were cadence issues with the unit. Despite clarifying this numerous times, there was still confusion there. What was said at the time was that below 60RPM we saw some impacts on torque (and thus power), but we didn’t see any issues with the cadence itself.
I tested the cadence range down to 30RPM, and up to just under 200RPM – against a known good. In this case that ‘known good’ was a traditional magnet-based cadence sensor. (Fun testing aside, it’s actually interesting to see the Stages PM drop off at precisely 30RPM. 31RPM is good, 30RPM gone.)
Taking a look at an indoor plot first, this is cadence of the Stages cadence vs Bontrager magnet cadence sensor. The graph is the 10-second running average plot, variation shown in RPM. Really do take note of the scale here though.
As you can see the average difference was between 0 and 2RPM. But again, that’s because there’s going to be some reaction time delay there from an electronics standpoint – so even just a single second delay would show up here (delay caused by transmission or recording). Said differently: They look basically spot on.
Now, here’s an outdoor ride (the Vegas one):
In this case you see more variability because of stops and starts being a factor and the data time slice needing to be just 1-2 seconds. So from a post-ride data analysis standpoint, it’s actually relatively difficult to see. To exemplify this, I went ahead and looked at a few of those areas where there’s divergence.
Now, you may be asking ‘Why don’t you just slide the entire data plot a few seconds?’. Well, when I did that it skews off the power. Meaning that while the power aligns fairly well from a timecode standpoint, the cadence does have a slight delay in it. Not enough that you’d notice it out on the ride, but enough that you notice it when you stop pedaling altogether (which is the case above).
It’s one of those things that’s much easier to see when displayed on a head unit because you can look at both units at once and see that even though one might be delayed .5 to 2 seconds, it’s showing effectively the same thing. For example, if I stop pedaling for an intersection. One unit might take 1 second to go from 90RPM to 0RPM, whereas the other might take 2 seconds. Thus on a graph it would look like there’s a ~90RPM gap, when there’s not. They’re both measuring it correctly, it’s just that there’s some internal communications and recording differences.
Again, I’m simply not seeing any issues with cadence on a road bike (nor was I seeing issues before) – either real-time indoors, outdoors, or in analysis afterwards. I don’t have a mountain bike, so I can’t in those circumstances. I do however have plenty of cobbles in Europe though – and saw no issues there.
Pacing and Wattage Stability:
One of the core areas of concern with the previous firmware was the instability of the pace. While power meter users will note that wattage on power meters fluctuates second to second, the initial Stages firmware introduced too much variability in my opinion – even while using smoothing options.
The best way to exemplify this is to simply show it. So I went out and captured some simple steady-state riding down the street. Nothing complex here, just riding on mostly flat ground. There’s no fundamental difference between riding on flat ground or a mountain from a strain gauge standpoint, it’s all just ‘effort’.
Here’s the video clip of steady-state riding. In case it’s not clear, there’s three head units, each labeled with Stages (left), Quarq (right), and PowerTap (top):
As you can see, I included instant power (top), 3-second (3s) power (middle), and 10-second (10s) power (bottom) on the display. All three ebb and flow together pretty much together.
Comparing Bluetooth Smart and ANT+ from the same unit:
After publishing this update earlier this morning a few of you asked about the Bluetooth Smart aspects, specifically focusing on comparing the ANT+ data coming from the Stages unit to the Bluetooth Smart (aka BLE) channel. As background, the Stages Power Meter is the first power meter to offer dual-broadcasting of data across both ANT+ and Bluetooth Smart, ultimately letting the user decide what devices they’re going to connect to the unit.
On the ANT+ side you have all the traditional power meter head units (i.e. Garmin, Timex, CycleOps, etc…). Whereas on the Bluetooth Smart side you have cell phone based applications, today limited to those on iPhone 4s and higher devices, as well as newer iPad/iPod devices with Bluetooth 4.0 in it (which is required for Bluetooth Smart). There is not yet compatibility on either Android or Windows Phone. I dove into the Bluetooth Smart aspects in more detail in the original review.
But I didn’t spend too much time either in the original review or in the update looking at comparative data from the Stages Power Meter when analyzing both data channels at once (ANT+ & BLE). So since I had a longish trainer ride today, it seemed like the perfect opportunity to give it a shot.
The setup for this was relatively simple: I had an Edge 800 recording the Stages ANT+ power stream, and then I had an iPhone 4s with the Wahoo Fitness App recording the Bluetooth Smart stream. I use the Wahoo Fitness app because I feel it’s the most complete app out there for data recording and analysis. It doesn’t have all the ‘community’ features of some other apps, but when it comes to data and getting data in any format on earth with reliability – it rocks that boat.
This then gave me a slew of files. Oh and for fun, I was also recording the PowerTap and Quarq concurrently – but we’ll ignore those for this test (I have included them in an updated set of raw data files however at the end of the review).
After getting all the data consolidated I started by throwing it into a 1-second chart:
Interesting, you do see some interesting variations there between the two plots – which I’ll get to in just a few moments. One track is a bit more ‘tapered’, while the other more volatile. But does it have an impact on segment averages?
Let’s first look at all the segments of my workout from today. Comparing the average wattage and cadence of each segment along the way – some as short as 2 minutes, some as long as 15 minutes. Plus the overall averages and max’s.
Again, near-perfect comparisons doesn’t tend to be exciting. But the above is pretty astounding. It’d be difficult to achieve that even with two Garmin Edge 500’s side by side recording the same power meter. I would expect that because it was a trainer ride, there’s slightly less variability than an outdoor ride – so you might get a hair bit more variation there.
So why are there itty-bitty sub-1% variations (more like sub-.5%)? Well, the Bluetooth Smart channel in this case is updating more frequently. It’s not that ANT+ can’t do that (as in fact, I do it with the WASP units all the time as shown in this review). It’s just that the Garmin doesn’t record higher than once per second. Which means it may miss some stuff. Hence why you see the higher max value on the Bluetooth Smart side – it likely had a split-second sample where I peaked higher than the Garmin even saw. This also means that you see a touch bit smoother track on the Bluetooth Smart side as it’s not just picking one semi-random packet out of the air, but rather grabbing a bunch and averaging those for the ‘1-second’ data point viewable to us.
While this one test shouldn’t be considered the end-all-be-all of accuracy, I did want to include it for those who were curious. It seems to me that the data is pretty darn solid though.
(Again note that this test above is on firmware prior to the latest Bluetooth Smart update, which may address any of the tiny little variances I saw.)
Final Thoughts:
Back in my first review of the Stages Power Meter, I concluded with the following statement.
“At present, based on me (and only me) it would be difficult for me to swap out my existing power meter with the Stages power meter. There’s just too much variance and fluctuations in power. Do I think that Stages can get there though? Yes, I do. But I think it’s going to take time, and likely more software work.” – January 2013
Based on what I’ve seen, they’ve done that work (and put in that time) – into the software. The physical unit I have has not changed since the original review. It’s the same unit I’ve had since the very beginning. They’ve just updated the software within it. And they took a lot of feedback from the original review and addressed issues of concern we had.
For me, I have no issues in using any of the power meters I’ve used in this review – including the Stages. I do in fact from time to time pick different ones, and the data is generally similar enough that there’s no discernable difference. Further, in some situations (such as nonstop climbing with shifts in temperature), the Stages simply performed better than two other units. This likely due to its automatic temperature compensation algorithms.
As for Stages being left-only and doubling the power, for me (and again, just me), I’m just not seeing any issues there. It’s possible that others have larger discrepancies, or that those discrepancies could vary. But in my case it seems pretty consistent across a wide variation of rides and riding conditions.
I think probably the biggest takeaway here is that no particular power meter is perfect. Anyone who says that there is, is sadly mistaken.
Given all that, here’s the updated Pros and Cons table:
Pros:
– Cheapest direct force power meter on market today
– Easy to install. Silly easy.
– Tons of crank compatibility options
– Accelerometer based cadence measurement works really well
– Utilizes standard CR2032 user-replaceable battery
– Automatically compensates for temperature changes
– Lightweight – 20g
Cons:
– Left leg dependent, simply doubles left leg power
– Total power could be highly impacted by your left/right distribution (but I didn’t see this)
– No method of end-user calibration validation (for advanced users)
– Doesn’t support Rotor cranks/arms as of today, or carbon crank arms
Thanks for reading! And as always, feel free to post comments or questions in the comments section below, I’ll be happy to try and answer them as quickly as possible. At the end of the day keep in mind I’m just like any other regular triathlete out there. I write these reviews because I’m inherently a curious person with a technology background (my day job), and thus I try and be as complete as I can. This isn’t my full time job. But, if I’ve missed something or if you spot something that doesn’t quite jive – just let me know and I’ll be happy to get it all sorted out. And lastly, if you felt this review was useful – I always appreciate feedback in the comments below. Thanks!
Finally, I’ve written up a ton of helpful guides around using most of the major fitness devices, which you may find useful in getting started with the devices. These guides are all listed in the ‘How-to’ section. Enjoy!
Note: Raw data files used in this review are available here. Notes are contained within each folder.
FOUND THIS POST USEFUL? SUPPORT THE SITE!
Hopefully, you found this post useful. The website is really a labor of love, so please consider becoming a DC RAINMAKER Supporter. This gets you an ad-free experience, and access to our (mostly) bi-monthly behind-the-scenes video series of “Shed Talkin’”.
Otherwise, perhaps consider using the below link if shopping on Amazon. As an Amazon Associate, I earn from qualifying purchases. It doesn’t cost you anything extra, but your purchases help support this website a lot. It could simply be buying toilet paper, or this pizza oven we use and love.
Just to make a pause on battery drainage (hopefully to be resolved on the near future…..).
Does anybody know how to interpret the new data: pedal smoothness and torque effectiveness? Both data shows two percentages (obviously, there are not one for each leg)….so what do these data mean? Any clue?
Here is food for thought on battery drainage. I am not saying this problem solves for all because there seems to be some real legit issues with moisture. I do not own a Stages unit and I am here trying to decide.
That being said I have a Garmin 500 and have noticed that I can go for a ride come back home take it off the bike and whether I plug it in or hook it to my computer it will stay in the on mode unless I specifically shut the power down. That being the case whether my bike was in the garage or in the house it would stay paired to something like the Stages unit until I specifically shut it down. I know I have friends who come in for a ride plug their Garmin type unit in and may not be able to ride for days but the unit stays on and even when you shut it off and plug it into power or computer they auto turn on.(the issue is probably more likely with the Bluetooth than the Antenna + but is possible for both) Well the math is easy 24 hour days on for three to four days. The battery drain would be more severe as well as constantly on for days straight compared to on and off after 2 to 6 hour rides so the 200 hours would go out the window as constant drain is different than on and off.
Again just food for thought and maybe it will help some.
As John says pre-2.0.37 software they thought that was the main issue – but that didn’t stop mine draining batteries for fun. My latest one has arrived and fitted – so we’ll see how we go this time!
Nice bloke from Stages is sending another replacement via Saddleback. I email SB to ask them to let me know when it arrives. Today, I get an email from them asking why I’ve been dealing with Stages direct and asking me for a whole load of info about the problem, what the serial number is, why I got a replacement direct from Stages (erm…because they said they’d send me one…) and generally making me feel like I’d been a naughty boy. They also told me that “according to their records” my cranks both came from Sigma sport. Nope – neither of them did.
Anyway – their email says when they’ve got the info they’ll “decide on the best course of action” – which is worrying as I’ve heard that they’ve tried to wriggle out of things by saying it’s “not a warranty issue” (which is a massive contrast to Stages, who sent me a replacement without me needing to return the one I had).
I’ve told them I don’t want them to “decide on the best course of action” – I just want my new crank!
That doesn’t sound good… I think SB have dispatched mine today, so I’m ok if this one works fine! Perhaps I’ll go for the duct tape solution mentioned above as a precaution!
Hi Ray – your reviews are OUTSTANDING – thank you!
I’ve recently started having issues with my Stages & Edge 500 losing synch/pairing. I am setup with the ANT ID stored in the Garmin. Whene power numbers disappear, I’ve had to. Stop, remove the battery, replace and let it re-connect. It is a new battery an latest Stages firmware… Any suggestions?
As an aside – I find your comparisons with the CompuTrainer super useful. I use power to target race and training pace and I train indoors on CT. Consistency and repeatability between these devices is MUCH more useful to me than what the actual numbers are. Ultimately, I’m training and riding my numbers, not comparing my numbers to other people’s.
Hmm, that’s a tough one – and very odd. It almost sounds like the battery might not be snug inside the compartment and then perhaps a bump dislodges it. Any chance you can fold up a tiny itty bitty bit of paper between the battery and the door and see if it holds it tighter?
Got ya covered. Start the warranty process. It’s loose Inside the unit.
Check the internal tabs and see if they are all still intac.
My stages is coming up to 12 months now (brought 04/13). New I had lost one tab about 6 months ago. But over the last 2 months battery life has got worse and it was dropping out at when coming to a complete stop.
So after a pull apart. The internal tabs,not cover has crack and broken off over time. Current fix – 3mm padding with a zip tie. Works fine and the battery life has gone back up too. The drop out started after a real sweaty roller ride.
Anyway – I brought mine from the america when I was on holiday so I have emailed stages to see if I can fix the warranty locally. (Australia) as I have a 4 day stage race to train for.
Warranty process worked very smoothly – sorry for the late reply, thought I had responded earlier. New unit works and Stages was very supportive (once I was able to get in touch with them).
I too have just begun to have a battery issue. Only lasts for a few rides indoors. New firmware made no difference. Then upon close inspection, noticed the battery door was loose. I have already had my cover replaced because of broken tabs, but now the issue is with the internal tabs in the unit itself. two or three are broken into small pieces. I am assuming that the “bad batch” of plastic used for the cover was also used in the unit itself. Just submitted a ticket at stages and hopefully they will take care of me despite my warranty was up a few months ago.
First off, great review (update) DCrainmaker and thanks for taking the time to do it. I have ordered a stages PM but haven’t received it yet, I see firmware updates for the unit are possible, but done with iPhones and iPads. The problem I have is, I have all Android devices now minus an old iPhone 3Gs that sits in a drawer but does work still. My question is, are there any other ways to update the firmware since I don’t own a newer iPhone or iPad. I have a Galaxy S3 phone and a Galaxy Note 10.1 tablet. Am I just out of luck to update in the future? Hopefully the Stages PM will come with the latest firmware to begin with, but future updates may be a problem to get. Not sure if anyone else has asked about this issue.
Thanks for any replies concerning this issue from anyone on the board.
★Please refrain from starting an apple/android war
Yup, as Mike noted, unfortunately at the moment it’s only iOS. Now, Wahoo is very near finalizing their Android app release. And while that’s not Stages, it’s the same company that Stages uses for much of their iOS development, thus, I suspect we’ll see Android based apps eventually hit Stages.
That said, like Mike noted as well – it’s really just a case of finding a friend somewhere to update. The updates from Stages are very infrequent. I think the last (new) one was many many months ago. So it’s not a weekly sort of thing. The only process only takes a minute or two.
Firmware 2.0.38 (?) was pretty recent – although my (fourth) replacement crank arrived with the latest firmware on. It’s pretty hard knowing what they’ve changed, as there doesn’t seem to be anything on their website that tells you when they’ve released new stuff.
Yeah, there was one in early January that was the update for high-speed data/some of the other PM metrics, as announced in September. But I think that’s been it since last summer.
I have asked a few times for a simple firmware change-log on their site somewhere. Mostly, so I can simply reference it in the Week in Review post. Even if it’s just one line-item with a date, firmware version, and then “Performance improvements”.
A log w/ release numbers and dates would be FANTASTIC. See what changes were made, where I’m at along the releases, and decide how much I need/want to bug some iOS user to help with the update. :)
It even appears that the latest Wahoo Utility app for Android lets you update the firmware of the Stages. I installed it on my phone (Galaxy S3), and it connects to the Stages, reads my firmware (2.0.38), and offers me to update. I didn’t dare trying, but reading that Ray says Stages and Wahoo work together (or use the same app development company), I guess it’s legit. A bit strange that they don’t mention this possibility on their own website, though. I guess a lot of people are really waiting for a firmware update path for Android.
Thanks for the link!
I decided to give it a try and downloaded the Wahoo Utility App.
A few moments later, it detected the Stages correctly (and warned about the low battery – 21% ) and proposed to update the firmware from 2.0.38 to 2.0.48.
The update process completed smoothly and now my device is up-to-date.
Great to know I no longer need my neighbor’s IPhone! Thanks again.
I downloaded the wahoo utility app and it recognized my stages and indicated a firmware update from xxxx.38 to xxxx.48 was available. However, it fails to update when I attempt to update with my GS3. Back to the drawing boards I guess.
Apparently for the update to be applied, the battery percentage must be higher than 20%.
It may also be the meter going in standby mode after a few minutes. I turned the crank a few times to keep it alive – but did not touch anything as soon the upgrade process had started.
No problems here…
Chances are you will have there will be a member of “friends and family” who will have an Iphone. The update takes 3 minutes and the app download is free from the app store. Might cost you a drink or coffee while you’re waiting. I installed my stages 2 weeks ago and even though it is brand new the app did an update immediately. Good news it takes minutes and worked first time
Hi Ray,
Just wondering if you had any insight into use of the stages PM with the Fenix / Fenix 2 with regard to the wrist mounted drop outs.
I have a new Stages PM and it pairs and calibrates just dandy with my FR 310XT but it drops in and out frequently if worn on the wrist (not at all if mounted on the handle bar / stem).
Should I expect better same or worse results from a wrist mounted Fenix 2 ?
Unfortunately I have temporarily removed the Stages on my bike so I can test the ROTOR Power Meter (the two are not compatible, due to being in the same place).
Fwiw, I haven’t seen any issues with wrist-based dropouts though in rides thus far, and I’ve been testing it against both a pair of Vector pedals as well as a PowerTap.
Thanks for the hugely in depth review. I have to confess I have not read all the comments so I hope that I am not repeating anyone here.
I suppose that this is more of a powerTap question than a Stages question but still relevant I think. I currently have a powerTap and plan to change to a Stages when I get a new bike.
Did you do any testing that uncovered greater differences between Stages (and Quarq / Vector) and the powerTap when the chain was badly maintained or filled with mud? I have heard mention before that a powerTap measures after the chain so it will be a slightly lower reading after losses from no oil or rust ect.
As I am moving from one to the other I am wondering if the readings might go up because of this. I suspect that the loss is so small that it cannot be measured.
Great reviews, so detailed and informative. Ray your site is my go to for any reviews of equipment. You seem very transparent and unbiased too which really benefits us the consumer but also if a company actually cares about the consumer they only have to read your review and go to work on the improvements.
Keep up the great work mate.
Isaac Far North Queensland, Australia.
I wrote to the EU distributor (info@stagescycling.eu) last week, and got an e-mail back 2 hours later. I have now received a new battery cover, and hopes that this helps solving my problem.
So it seems like that luckily, the EU distributor have another approach to customer service than Stages USA, it has been 15 days since I wrote to them first time (3 followups), and I still have not heard anything back, that really pisses me off :-(
Thanks for your comments. I’ve upgraded from a Powertap G3 to Stages and I couldn’t be more pleased. But I don’t think I can sell the Pwertap for even half of what I paid originally.
Well, my recently acquired stages worked very well for 3 weeks then started eating coin-cell batteries at an alarming rate. 3 Batteries dead when preparing for a ride, 3 days in a row…. I have been careful at protecting the electronics from water by using duct tape across the unit covering all the electronics pod with a tight seal all way round. This is on top of a correctly fitted cover with red o-ring. In any case not been out in a lot of really bad weather, so 99.9% sure that its not water related. Have of course also updated the firmware.
Went back to the retailer, who explained that they could not replace the unit as the specific model I had just bought was out of stock, but that they would inform the UK importer and advice me when they have stock so the unit could be replaced.
Since then I am now removing the battery after each ride, then refitting and re-taping with duct tape immediately before the next ride. Counting my riding hours and curious as to how many ours I will get on a coin-cell while I’m waiting for a replacement.
For good measure I emailed Stages to inform them of the problem and ask if they had any other advice and like Michael have not had any reply. So perhaps the recent success have taken over form serving the customer, or perhaps they are busy painting crank arms “Sky Blue”.
Positives: Its a very neat solution and so easy to install and manage offered at the right price-point.
Concerns: The Battery pod cover does look a little flimsy (but is easy to operate) Risk of water ingress has been raised by a lot of people but its so easy to upgrade with a strip of duct tape.
Alarming Pattern: Battery drain is a failure mode that seem to occur for lots of users at a high repetitive rate. Really would be nice if Stages could acknowledge this and focus on getting their payning customers sorted on this issue.
My action plan:
1) Keep using while removing the battery between rides
2) Expect prompt replacement with a unit that works (Or a firmware upgrade that stops the drain)
3) Get my money back using UK “Trade descriptions act” (Battery usage 160+ hours specified, vs actual less than 4 hours.
The life of an early adopter…. :) – SRAM Hydraulic Brakes, Garmin 810, Stages Powermeter
Mike, that’s really worrying that this issue is reoccuring on a unit that Stages swear blind has solved every issue. My Ultegra 6800 is fine after about a month – but then so was the last one! I also have a Dura Ace 9000 on my summer bike that I’ve not used for a few months, but the battery is completely flat, so I’ll be interested to see how that goes with a new battery in…
Thanks for all your in depth reviews, I for one really appreciate the effort you go to and the information that comes from that effort. I am better informed.
So…I am on my second Stages. I have tried to make it work with my 910xt and a friend’s 500. The first one that I sent back would work mostly with my 910 if the 910 was close to the Stages. When I was in my aerobars, it didn;t work. So they sent me a code to send it back. No email communication, the box just showed up. So I got the new one and have been futzing with it for weeks. It refused to pair for longer than a few seconds with 910 and same thing with a 500 that I borrowed from a friend. I asked if they wanted to try a third unit or send my refund. We’ll see…
Summer bike came out on Monday after a few months’ hibernation. Replaced battery and seal/door, updated firmware, rode bike. Went to bed. 24hrs later – flat battery.
So this is now the 5th crank I’ve had with this issue – and Stages don’t seem to be any nearer identifying the problem.
Saddleback have insisted I go via the retailer, so I have emailed them making it clear I’m not going to return it so someone can “inspect it” – i expect a new crank (which to be fair Evan from Stages says they’ll send). Merlin made me return a Di2 battery holder for “testing” which promptly disappeared for two months, with the only updates provided when I chased them. If I hadn’t had a spare I’d have had no bike during that time.
Mike – i’ve mentioned you to them as an example of a new model, new seal customer who’s almost certainly never had water ingress – any joy from them with yours?
I’ve got the battery drain problem as well – now on unit no. 5 (XTR Based). It does seem to be triggered by damp weather in my case – not always direct rain. The shed where my bikes are kept does get a bit damp and (mostly) the battery case is dry.
The local Australian distributor has said that there was a bad batch of the ‘new’ cover design which are being replaced.
Sigh. Such a great little unit but I’ve probably spent almost the price difference between stages and Quarq on CR2032 batteries now!
Still not convinced that its purely moisture though…
Aaaaaargh!! New in every way Ultegra 6800 (my 4th) was fine for a month, I guess 50 hours of riding. It’s not been used for a week or so as I’ve been using my summer bike. Got it out today – flat battery. I’ve fitted a new one, fires up straight away – but all the signs are there that the same fault has manifested after about a month – the same as with the other units.
If I’m doing something to make this happen, you’d have thought Stages would have worked out what it is by now, wouldn’t you? This is soooo frustrating!!!
Andy, you must agree that there is something not right here. There must be thousands of Stages power meters out there, so if it was a simple generic problem, we would see more complaints here. Yet you have had 5 crank arms fail. Logic would dictate, that it is something in your environment causing the problem. I’m thinking 2-way Bluetooth communication or something triggering the accelerometer. You could try to move the power meter to another location.
It would of course still be a fault in the power meter, but it would explain the few observations.
I’d have agreed, Uffe, if Stages had managed to identify what’s causing the problem (they’ve had the faulty units to look at!) or if they’d come back and said “we can’t replicate it”.
On one of the cranks it was very obviously water ingress – there was rust in the battery compartment. That’s nothing to do with its environment – they’re supposed to work in the rain.
The other thing is these cranks are on bikes that are used “normally” – i ride pretty much every day, in normal UK weather. I don’t do anything “unusual”. They’re stored in a shed away from the house (although the issue has occurred when i brought my bike into the house to see if i had a “magic shed”. Generally they’ve worked fine for about a month, then they fail. Whilst i accept there are thousands of working cranks out there, there is something that fails in normal use – if I knew what it was and it didn’t involve emigration (interesting that nearly all the examples of this failure – and i’m not the only one – but thanks to great service from Stages i’ve had several replacements – have been in the UK) then i’ll do it.
But all i do with them is put them on my bike(s) and pedal!
A guy on Tri Talk noticed that when he replaced the battery his Garmin could “see” the unit without turning the crank. He’s replaced the battery and his seems to have regained its ability to switch off.
I’ve just been and checked BT and ANT+ on the Ultegra crank that had a new battery about 4hrs ago – it’s still transmitting both BT and ANT+, despite the crank not being moved – so the issue is that it’s forgotten how to turn off. maybe it’s caused by a new battery – as on all occasions my units have worked ok for about a month (about 45-50 hrs of use) then once the first new battery is put in they seem to lose the ability to shut down.
Have you tried taking your battery put after each ride? My second unit won’t connect to my 910 or my borrowed 500. They are telling me to check the firmware on the 500. So…a couple more weeks of no functioning power meter. I’m at the point where I want a refund and get some Garmin pedals. Has anyone successfully gotten a refund?
Hi, i’m looking into stages as my first use with power.
My race bike with shimano dura ace 7900 and training bike 105 5700.
Is it possible to use a dura ace 9000 or 7900 unit on 105 5700
Many thanks Steve
Stages Power Meter crank and Powertap PRO+ wheel fitted to same road bike on the same ride.
Video is of the recorded telemetry overlaid on the GOPRO video of the ride.
If mine were that close I’d be jumping for joy. I’ve run a few test against my powertap and it’s consistently off by 20-30 watts. Doing more tomorrow but their credibility with me is pretty shot so far. Doing a road test is great for summary data but testing it on the trainer pretty much convinced me its not even close.
Sorry, so the cadence sensor drops the wattage by 20-40 watts on a Stage vs. Powertap G3? I’m actually getting a ton of smoke blown from stages on this and it’s clearly off. They are supposedly testing it in house; however, I’ve been told the guys at Shimano here in Cali tested these meters and are seeing the same results – off by 20 or so watts. Mine has been off by 26-27 watts consistently regardless of output. Maybe a bad run but kills their credibility with me.
Remember, it’s left-leg only. Thus, your left leg is quite likely lower powered. That’s a fundamental way that the Stages work, and doesn’t have really much to do with the unit.
26-27w sounds incredibly precise however, as I’ve never seen consistency between any two power meters that varied by a set amount of wattage at any level. Mostly, because I’ve never seen data comparisons between PM’s that were exactly the same at any power level (they usually are percentage based).
I only use watts because its pretty much consistently off by 20-30. Percentage would be I’m sitting on the trainer testing, pacing around 110-120w and the Stages is off by 25%. At 150-160w if reporting approx. 18% lower, etc. You honestly think that is incredibly precise?
Update that Stages took it back, tested against a SRM and Quarq with the meter being perfectly accurate. I’m seriously struggling with this.
Here is the thing. If its left leg only that’s fine. If my leg was say weaker by 10% wouldn’t the the variation be progressive, say 100 watts, off by 5, 200 watts off by 10 but it’s consistently off by 20-30 watts regardless of output. I guess the question then is which one is accurate and I lean toward PT.
Had a buddy local riding PT G3 wheelset and bought a stages meter recently. We just tested swapping wheelsets etc tonight with the same results off by 20-30 watts.
It really is left-leg doubled. Stages clearly states that on their site (as does the review).
The reason you’re likely seeing variance is that people have different balances at different levels. For example, at super-low intensities (soft-pedaling) I’m balanced quite differently than mid-range (very balanced) and again differently a different direction above FTP. If you check out others that have done some poking, you’ll find totally different results based on the individual. Tom A. on Slowtwitch posted a graph of his, which was almost inverted from mine. Making it even more complex, we tend to differ on different days in different ways – such as longer in a ride versus being more fresh.
Essentially, we all differ. And that difference is the fundamental key to understanding whether or not the Stages is the right fit for you.
I’m not the only one seeing this issue. Going to throw our G3s up against a SRM and Quarq so should know which one is off here soon enough. link to forums.roadbikereview.com
I’m still not sure exactly what the issue is but the constant deflection from Stages is its an imbalance. Same exact imbalance me and two other guys with these meters are seeing local. I finally got extremely fed up dealing with them and scored a brand new 9000 SRM. Quick test today absolutely confirms what I knew day one. It’s actually worse against the SRM being off around 40 watts, guess that’s pretty precises being off 20% at 200 watts? So that’s two sets of powertap wheels and an SRM with two different riders getting the same results. Odd.
As I’ve told them I honestly could care less about the technology, bores me to death. It either works or it doesn’t. Personally I’d cut back on Starbucks for a month and pick up a Riken instead.
Cheers fella, Yeah – 2 garmin 705’s with the same firmware (3.1) and same settings, I wanted to reduce as many variables as possible and have always found the 705’s with that firmware to be rock solid (at least for me)
I am really interested in this power meter, since it is one of the least expensive and easiest to install.
But I was wondering if there is anyone out there that does not have any issues with this power meter? I understand most people here post about the problems they have with this Stages, but I also would like to know if anyone is completely happy with this power meter?
I bought one 9/13 and had it replaced a few months later do to faulty seal and it got wet. The new one I received 1/14 has had no problems other then the battery cap busted a prong. They immediately sent me 2 new caps. I have been very happy with this one. No battery drain. CS has been on top of every email I sent from the start. I highly recommend getting one.
Owned one since beginning of the year with 2000 km on the same battery. To be fair it sitting on my nice bike, and did not ride in any serious wet weather yet.
A comparison on the Tabayesco climb, Lanzarote (10,3 km 5,7%) rendered 264 W avg. on Stages and 271 W using bikecalculator.com. Comparison on the trainer with the Power2max I have on my other bike is also favorable.
In other words I’m very happy about the Stages power meter, but if course concerned about the reliability issues described here, and I think Stages should get to the bottom of this, and be more open about it.
Great product. But the reliability Ian an issue. Knowing 6+ people that have gone through more than 2 units each is a concern.
Wet raining is an issue. I had mine replaced due to the internal tabs breaking. I put a fresh battery in and taped the crank in electrical tape. Even though it’s a new unit and meant to have the new seals
A friend picked his up 2 weeks ago – did a wet ride and now have drop out issues. Told him to leave the battery out. He’s now getting a refund since the downtime is major in Australia.
I have given my new stages back to my lbs to look at. Out of the box it paired perfectly with my garmin 510 and has produced very conisistant readings. Unfortunately they are consistently 50% higher than my powertap. I have previously compared my powertap on vbarious mountain climbs with power calculators and normally the powertap was slightly higher than calculated (within 2 – 3 %).
The stages gives results such as 3 – 4 hours at 290 watts average and average heart rate of 110 or less. My estimated 1 hour threshold at about 520 watts very unlikely.
I had trouble pairing it with my suunto ambit 2 and virtually had to insert the watch inside the power meter After pairing i could not get it to detect the stages whilst riding. I am wondering if the transmitter is a little weak as i expect the suunto aerial is also potentially weak judging by how close you need to be for it to pair with any ant+ transmitter.
Ray, I wonder if you can share the files where you ran a stages on a computrainer, I’m interested in calibrating the stages vs a computrainer as I test and train on a roadbike on a computrainer and have the stages on my mountain bike which I race. I realize they will be different and have no issue with that but I’m trying to determine how different they might be so I know what to set the FTP on one to be as close as possible to the other.
Unfortunately my mountain bike has a 142×12 rear axle and can’t be placed on a computrainer to do this sort of test myself!
I’m having problems with battery drain and I’m unable to connect with Stages App to update firmware. My Iphone is unable to find the power meter even with new battery installed. I have been in contact with Stages and they gave me some ideas to get the bluetooth issue to work. But nothings works and I’m a bit frustrated. Stages EU will send me a new battery cover and o-ring. But I guess that will not help unless the new cover makes the battery fit better or something if now that’s a reason for battery drain.
Is there anyone else having BIG problems connect your Iphone with the power meter? I have tried both with my Iphone 5s and Ipad Air with no luck.
Erik. Hold power button & standby button on your iPhone until apple logo appears. This will clean up any ram being used & refreshes iPhone. Then try again.
Erik: Just an oddball suggestion. Since you said you had paired the Stages with multiple BT devices (your 5s, your Air), is it possible that you are paired with another device — and that’s why the Stages app can’t see the power meter to update its firmware?
To test this, banish everything but your bike and your iPhone from where you are. Maybe even go a block or two down the street! Put on a tinfoil hat! Whatever… Now try it. Any change?
And the battery door is a bit problematic. If the door isn’t inserted all the way, you might have a bad power connection. Just for a test, try taking the o-ring out, but a fresh battery in, do a happy dance. The door is much easier to insert now. Any change? If so, now figure out how to get the o-ring back into the solution…
Not associated with Stages, just a happy owner. Yes, I’ve had both these issues (“D’oh, my darned iPad is talking to it. WTF!”). You may well have another issue, but perhaps you’re like me and find it’s something simple and stupid in the way.
Just wanted to thank you for the “happy stages user” comment because with all the negative input I have not dared buying one.
I’m very tempted to get one for my mountainbike. There I don’t see left-right power as an issue and would still like to get an idea of the power output without weight punishment and not having to move away from my pretty and well function XTR crank set.
Would be great to hear from happy mtb Stages users!
I have now tried to shut down every other device with bluetooth, closed all apps on Iphone and did another try with/without o-ring and battery cover on. It’s impossible to find the power meter with bluetooth. If I turn my Edge 800 on, it’s connected directly with ANT+..
Since there is a battery drain issue which could be a result of water leak, there is no sign of this inside the power meter but I have one ride in heavy rain in the last couple of weeks. Battery drain issue started this week..
Is it possible that the bluetooth signal can have been effected by water/moisture but not ANT+? I will wait for the new battery cover and see if that can solve some issues otherwise I have big hope on Stages god reputation about replacing “broken” devices.
Despite this I have been super satisfied with Stages power meter, and my faith in Stages is not hurt yet..
Do you mentioned some connectivity problems between the Stages Powermeter and the Garmin 910xt? My Stages arrived on saturday. It works really fine with the iPhone4s (Bluetooth and Wahoo ANT+ Dongle), but with my Garmin devices (Edge 800 / Forerunner 910xt) i have huge data dropouts. And both Garmin devices do not recognize the Stages PM as a cadence sensor.
A look into the internet showed me, that this is a common problem and is a issue of Garmin… Take a look here:
Yes, it’s a 910XT thing and affects more than just Stages if in aero position. I asked them in the past and they said they were working on something there, but it sounded like more guidance than anything. I’ve got it on my to-do list for an e-mail this week to see what’s up/new.
As for Garmin devices recognizing the Stages as a cadence sensor, that doesn’t happen. The cadence comes automatically when you pair the Stages as a power meter – it’s part of the power meter profile to take it from devices that support it (as Stages does).
thanks for the fast response. It would be great if you can keep me up to date. Cause i have to decide if i keep the Stages Powermeter or send it back. At the moment the Stages PM is pretty much useless for me… :(
I managed to get a cheap second hand stages off ebay and I was wondering if its normal for it to show far less power on the turbo than on the road? On the turbo I struggle to put out more than 2W/KG, but my FTP is about 4W/KG, any idea why?
Some people struggle to put out power on trainers (compared to outdoors), and for others it’s the inverse. For me, it’s the inverse. I can pump out trainer power all day long, but on a flat course it’s far more difficult for me. But not quite the separation that you’re looking at there.
Cheers, I am really confused as to why the difference is that much – admittedly I do hate trainers so I use it as little as possible and its now been packed away until next Winter anyway!
Guys….the Garmin 510 update from 2.8 to 2.9 included this comment:
Fixed an issue causing ANT+ sensors to become disabled when searching for a new sensor.
I was having issues with my garmin losing connectivity to the Stages like people are commenting on here. As soon as it the garmin was updated the issue went away.
The other thing I recommend is programming in your Stages Ant ID instead of letting the garmin find it. If your Ant id is 6088 then input zeros in front of it in the Ant id screen on the Garmin…i.e. 0000006088 and it will pull it it up right away.
I borrowed a friend’s 500 and did an update and that didn’t seem to help. I cannot figure out how to manually enter ANT ID. and I couldn’t find it in the manual. Can you give instructions? Thx.
Sure. My issue was with a Garmin 510 not the 500 but the instructions below are for the 500 since that was your question. I am not sure however if your 500 literally can’t find any power unit it may not pop up the “Sensor Details” option in the Ant+ Power menu. Hope the below helps.
Hold down Page/Menu->Bike Settings->Select Bike (i.e. Bike 1, etc.)->Ant+ Power->Sensor Details->Highlight the Sensor ID & hit Page/Menu->input the Ant+ID with zeros in front of it if needed.
Hi,
I’ve heard good things about Stages and now see that Sky is using Stages, but my experience has been anything but positive. The first Stages powermeters that I used were earlier versions and had issues with connectivity and the battery seal. I know that Stages has made some improvements to firmware and the battery seal and so should have addressed a bunch of their first run production issues. But still, my first experience wasn’t great.
A few weeks ago I got a new bike with the Stages powermeter on a Shimano Dura‑Ace 9000 crank. The power seemed off (low) and I thought maybe it was the fit on the bike. So, I had the fit looked at and adjusted a bit, but that didn’t seem to improve the situation. So, I decided to test the Stages against a Powertap and found that the Stages power was 19% lower. That’s an unacceptable variance. Actually, I’d say anything nearing 5% variance is unacceptable. So, 19% is off the charts.
Have you heard of anyone else having this issue? Thanks!
Have you looked into testing your balance with a power meter that supports that (i.e. Vector, ROTOR)? Ultimately, the Stages simply doubles the left leg. As a result, imbalances will result in what you see.
Hi,
Thanks for the reply. I’ve been using a Quarq that has a calculation of the balance. I have worked on equaling out my balance and am usually 50/50 or 51/49. So, if anything, my power should be a tick up with the use of Stages.
I’ve talked to Stages and sent in my comparison files. They can see there is an issue and so we are going to send the powermeter back in for testing on their end to see what they can find.
When you did your comparisons, were the watts produced on Stages comparable to Powertap, SRM and or Quarq?
They were similar in most cases, however once I cleared my FTP level then things separated quite a bit (read: my balance became inbalanced). Check out my Vector review where this is shown really clearly.
I just purchased a Stages PM and seem to be having the same issues with the power being meaninfully lower compared to my tests on the computrainer. I’m running 30-35w low on the Stages at most levels above 300w and more pronounced up to 50w at levels around 150w. I seem to be more in the 10% variance range, which seems unacceptable. My HR had been telling me that the wattage seems low but finally tested it on the Computrainer (2 different ones) and seems to be consistently off. Did you get any result from Stages? I’m going to send them a note later today.
Jon, I sent the comparison files I made on the Stages and Powertap in to Stages and they agreed that there was an issue, so we set up for me to send my Stages PM back to them. I just recently did that and it arrived to them yesterday. Their initial comment was that 2 tabs on the battery door were broken which could be causing powers and therefore a lower avg. power reading. I guess that makes sense being that there have been so many issues with the battery door on the Stages PM’s, but I hope to know more today after they run some other tests.
Thanks for the quick reply. Let me know if you hear anything insightful from them on the issue. I’ve only got 5 rides under my belt with the PM and only one was outdoors but overall wattage felt low. I’ll email Stages and see what they tell me as well.
Stages did some work on my power meter and returned it to me this week. I got it on the bike and went out for a ride this morning. The power seemed to be where it should be. However, I’m not 100% sure that it’s correct because I didn’t run tests against any of my other power meters. But, based on the efforts I was doing and my corresponding heart rate, I’d say it was correct. I’m going to do a few more rides and if the numbers continue to make sense, I’ll have to say that Stages has corrected the issue with my power meter. If the numbers don’t look right, I’ll pull the crank arm again and run tests on my other bike against another power meter.
Kevin – thanks for the update and glad to hear the new one is more in line. I’ve been sending emails back and forth with Stages on the issue and sent them a comparison file of my Garmin vs. a Computrainer where I did 6 intervals of 5min at VO2 max levels. Looking at the data and averaging it out for the 6 intervals, I was 35 watts lower on Stages compared to the Computrainer. We’ll see what they say but at this point i’m resigned to lowering my FTP accordingly and using the PM as my main source (despite what that does to my ego). Appreciate the follow-up.
For those having issues with the 910xt, I have this unit and have not had any connection problems. I did skip the calibration this morning by accident and no power would register. I turned the watch off and then back again, calibrated per the prompt when you turn the crank, and it was good to go. Not sure if this helps but still learning the ins and outs of technology.
I got a new arm after my first one was having water ingress issues. The new one seems to be reading 20-30% lower than the old one. Unfortunately i don’t have another power meter or computrainer to compare against. So I verified this using a number of different methods (perhaps none 100% convincing in themselves, but together i think it’s pretty clear). Interesting to hear that others have had the same problem. My shop have been great and are getting me another arm to try.
I recently purchased a Stages PM for my road bike. I have been using it for a little over a month and have been very happy with the results. I spend time between two locations, and I now that I am cycling frequently enough (3 – 4x per week) that it makes sense for me to keep a road bike in both locations. I have been looking seriously at a couple of bikes that use FSA hollow carbon crank arms. My understanding is that Stages cannot work with a carbon crank arm because of the flex characteristics.
Stages recommends purchasing their alloy FSA crank arm and just using it with the carbon on the crank side. Does this make sense? Or is it better to consider swapping our for an all alloy crank? I definitely want a PM on both bikes and the Stages price point is appealing.
Love your work and always point anyone with bike tech questions in your direction. Recently bought a stages and have been having problems with my edge 500 and power dropouts. I emailed stages about it and they said that it could have something to do with the edge 500 loosing hrm signal and as a result it drops the pm signal in favour of trying to pick up the hrm again. I was wondering if you’ve experienced this and have any soloutions in terms of making the edge 500 prioritise the power meter and not the hrm? There are no problems when I’m on the aerobars but when I sit up the power signal drops immediately….
Hmm, I’m not too certain I buy that specific explanation. The ANT+ chip is multichannel and I’ve never heard of it dropping one channel for another, and certainly never prioritizing.
Now, I can buy there being a signal issue – though that’d be the first I’ve heard of on the Edge 500 (FR910XT is very common).
One thing to try is temporarily take your Edge 500/rubber band mount and stick it on your top tube of your bike (basically, close to the Stages PM). About half-way between the seat and the stem. See what happens. Helps to narrow things down.
Well looks like it’s started again. Had the new crank 3-4 months. Changed the battery before a 3 day – 4 stage race On Thursday. Popped up in the Garmin this morning the battery was near flat.
I even run elec tape over it. But I say it has got damp from the lovely race on Fridays road race stage. I’ll touch base with stages USA today and see what they say.
Does your current power meter have a red o-ring? The red O-ring plus the new battery door are supposed to prevent the battery draining issue due to dampness. I received a replacement back in January that supposedly had a redesigned battery door but i found out recently that one drained the battery after riding in the rain or after washing my bike. I received a replacement with the red O-ring. Hopefully the battery draining problem is fixed once and for all with this power meter.
I’m still wondering whether this is an initialization issue. It seems that the problems always start after a battery change. It’s a common problem with ultra-low-power electronics, that they do not reset properly when the battery is changed. I would try to short-circuit the battery terminals for a couple of days before mounting the new battery.
Ran my Stages for 6 hours in the rain two weeks ago, and still on the first battery after 3500 km.
Update: The replacement power meter with the red O-ring survived the first bike wash. So i am hopeful that my battery-draining issue has been resolved.
It’s not an initialization issue. The battery in my old leaky Stages power meter would work fine until i wash my bike. When i didn’t wash my bike for several months, the battery lasted just as long.
-Not for bragging rights but to validate my statement below.. bike time was 4:50 (112 miles). Body weight was 129 lbs and avg watts per kilo was 3.8. Stages (in my opinion) was the best option for the cost in weight, flexibility in wheel options, and overall dollar cost.
For anyone reading this and considering the options for a power meter… here is my experience. After hearing about stages from my bike shop (the owner a former CAT 1) and researching your review, I purchased the stages dura-ace 9000. Although I had to wait a few weeks for it to arrive, (this was nerve wracking with my A-race approaching rapidly) it was a very good investment. It arrived in time and I had a few weeks of training left to test it and recalibrate my strategy. If I understand weight to power issues correctly… this was the best option. For the cost in weight (ie how much more does it add in weight) it added a mere 20 oz vs. almost a pound of weight for the power tap. Additionally crank mounted power meters provided me a greater flexibility for rim options without purchasing multiple power meters. I.E. I used heavier and less flat prone clenchers for training saving the expensive tubeless tires ($120 ea) and rims for race day and allowing training to be harder as well. Another important consideration was cost. Stages was significantly less than other crank mounted systems. Therefore… and with your comments from your review, stages made since.
Stages was consistent over time and I knew what I was going to push on race day based on training… It was irrelevant (for me) if there was any difference between systems. I didn’t understand how improved accuracy (1 crank arm vs 2 etc… ) would help me speed up and yet conserve for the marathon. If anyone understands this then please let me know. I am assuming that even a 5% fluctuating variability (6 watts) is better than the calibration in electro-biological muti-stage systems (our legs). I had improved my performance significantly from the previous year, was second off the bike in my age group, and 58th out of 2500 overall counting pro’s. Power meters made a significant difference in my ability to conserve for the next leg of the race. I hesitated to go with the stages due to the newness of the technology and the likelyhood for bugs. It takes time to work them out. It always does. But the technology used in stages isn’t rocket science… (or is it?) so it shouldn’t take too much back and forth to get it close enough. It was a bet I was willing to take. Stages worked… I shaved nearly 2 lbs off the total bike weight (original zipp old tubulars and powertap were HEAVY! but a better option than guessing). I was able to manage (per strategy) output power over the full distance of the bike leg instead of guessing. That made a difference in my total race time. Total improvement was nearly 35 minutes from the previous A-Race and a 20% overall improvement in rank (I know what some of you are thinking here so I will add “without the use of drugs”).
Training and strategy were more significant than 2 lbs of weight, but having trained very hard and having improved that much, I had a chance at a podium. I wanted the best equipment possible. Stages won in a “due diligence” comparison analysis and during use it worked well.
Hopefully this is helpful for anyone who reads down this far.
I had similar problems with my 910xt. In the last weeks i tested a lot and it seems the
problem only occurs, when the watch is on my wrist and moving around (like turning/pronating
the arm, switching hand positions, etc.). When the watch is mounted on the handlebar/extensions
and stays in this position, the connection is good. No more data drops. I think the watch needs
a few moments to receive the signal. And when moving the watch around, the watch looses
the signal with bigger movements.
So i bought the Garmin Quick Release Kit, place the the watch on the handlebar/extension
and everything works fine. When i enter T1 i move the watch from my wrist to the handlebar
(leaving the strap on my wrist during the ride) and after the ride i move the watch back
on my wrist and everything works fine also during competition…
Nave the 910xt and I can’t get it to wok. It asks to calibrate, and then I get no readings. My three emails are going unanswered to Stages. This is my second unit. This one does the same thing with a mounted 500 as well. Mounting my 910 didn’t help..
Ultimately, it’s unlikely Stages is going to be able to solve this. I’m reasonably convinced it’s a Garmin 910XT problem, and they came reasonably close to admitting as such last fall (but never quite crossing the line).
Unfortunately there’s no hard and fast ‘will it work’ answer, since it appears to vary greatly on:
– Exact hand position
– Exact position of watch on wrist
– Which wrist
– Your body type
– Your bike type and what might be impact signal between crank and watch
– Tidal patterns
I kinda feel for Stages here, since they are at the mercy of Garmin on this, and Garmin is kinda trying to pretend that it’s a user issue. And, further, it’s actually not Stages – but rather appears to be many crank area power meters, even including Garmin’s own Vector (and Quarq’s units). It’s simply that there are more people buying Stages with the 910XT than Vector. I suspect that Vector buyers are more likely to have a separate Edge device (and informal data I have based on review comments seems to agree with that).
One would have thought that Stages has solved the battery drain issue by now. Unfortunately not. The battery in my two week old stages crank lasted only for 30 hours. Subsequent batteries lasted only for one ride. Stages will replace my crank (some mention of not going into sleep mode …. though this can’t be the only reason), however, in the roadie forum that I frequent a couple of people report the same issue. If you check other interne forums the same story pops up frequently. In a UK triathlon forum people ride already the third replacement crank. These are very recent reports and can’t be related to poor sealing or the software issue supposedly fixed by the firmware update.
It sort of looks like that they still haven’t figured what the real reason for the issue is. Never purchase a first gen product!
It is straightforward to test if the unit has not gone into sleep mode with the phone app. If it is not sleeping, the app will be able to connect to it, if it is sleeping then it will not. The time from inactivity to sleep should be 5 minutes in the later firmwares, so just let it sit for 5 minutes and then check with the app.
I’m convinced its a Garmin problem too. Just spoke with them about my issue — works on road but not in house on trainer. They suggested that my home wifi signal maybe scrambling the signal and the Garmin won’t read it. Sounds fishy to me, but I’m going to move to a different location in the house and see if there is any improvement.
An update from me and my battery problem – about six weeks ago both my Stages power meters stopped draining batteries – no idea why, but I assumed it must have been because I had a duff set of batteries – which I found amazing given I’ve used two different sorts, but I couldn’t think of anything else. Both have worked flawlessly ever since.
Over the weekend my Edhe told me the battery in my power meter was low, so I replaced it with another one of my “good” batteries (I also updated the firmware to 2.0.51 – anyone got any idea what that’s supposed to do?). And lo and behold, today my brand new battery is flat. I even used a paperclip to short out the power meter, as some people have recommended. So I think the issue I’ve been having is something to do with battery replacement.
What was interesting tonight is when I put a brand new battery in the meter still didn’t respond – but about five minutes after putting it in all of a sudden it “woke up”.
So either the new firmware has brought the problem back, or there is something that happens when you replace the battery – which inadvertently I got right a few weeks ago and then got wrong yesterday!
If your power meter is still under warranty, i suggest getting a warranty replacement. My current Stages power meter is the fourth one and i think this one is a keeper. It survived a second bike wash without draining its battery. My previous two power meters would complete drain their batteries within a day after a wash.
This is the second repkacement DA crank and I’m on #4 Ultegra – I don’t want to rain on the parade, but every one I’ve had has been fine til I replaced the battery. It’s not a water ingress issue – it’s something that happens when you change the battery.
I’ve just been and checked that the crank with the new battery in has gone to sleep – it has, then it immediately “woke” when I spun the crank – so we’ll see how long the battery lasts…
Answer? It didn’t last. Didn’t ride the bike for three days and when I checked last night the better was flat. Stages are now back to suggesting it’s (a) water ingress or (b) the battery terminals are squashed. They just don’t seem willing to accept the growing evidence that something happens when you replace the battery.
Regarding changing the battery, I have used my Stages for one month now, with no issues, but also no soaking wet rides yet (but I have washed my bike, and a couple semi-wet rides).
I have not changed my battery, but I have removed and replaced the battery twice (to test something), with (apparently) no ill effects. If the theory is that replacing the battery causes issues because the unit is then momentarily completely unpowered, then removing and replacing the battery should be the same as actually changing it.
I’m not dismissing your theory, but I think there has to be something more to it than just changing the battery.
I’ve had my Dura-ace 9000 stages for about 2 months. First 6 weeks was great but also no rain since I used my rain bike those days. Then, I had to replace the battery. After that, I had lots of problems. Also, I cannot tell if the battery cover originally came with one tab broken off or if that happened when I replaced the battery mid-ride one day. Anyway, the bike then got soaked in rain heading to a race. Despite new batteries, did not work. Then, I let it dry out for a few days and, with yet another battery, it started to work. But, that battery only lasted 1 week. Enter another new battery and I had trouble for a while getting it to find the power meter then it finally did and all has been good for a week. I’ve got the stages wrapped in two layers of black electrical tape until Stages sends me new battery covers. So, I don’t know if the issue is that it get wet or there is something else going on that is independent of the dampness issue. Stages has been pretty helpful so far. I’ll see whether the new battery door solves the problem. If not, I’ll ask for a replacement crank. Any thoughts? By the way, I’ve been running a power tap simultaneously (in case the stages dies on me) and, although I’ve not plotted any downloads, it seems to me that the stages runs maybe about 5-15 watts higher consisently, but otherwise they track closely. Any thoughts on that?
my stages v powertap comparison was very close – I run them side by side as well. Other people have more disparity. For me it wouldn’t be an issue as long as the stages remained precise (vs accurate), ie. if you put the same effort in it gives the same results. Also on my second satges which seems to behaving itself but we are out of the bleak british winter weather so it’s not really 100% tested.
More battery issues – I just posted the other day and must have jinxed myself because my battery went dead a few hours later after less than 1 week of use. I messed around with the new battery install and it seemed like it took a good 20 minutes before I finally got my garmin to “find” the power meter. So, back in action but this stages is killing batteries in less than 1 week. I’ve heard one comment that without the right battery cover, the battery won’t stay properly seated and maybe that’s why they keep going dead. But, I’m feeling like my patience with this is wearing thin. I’ll try the new battery cover when it arrives and if that doesn’t fix it, will ask for a replacement. Any thoughts on why it would take so long to get the garmin to find the power meter after I insert a new battery? Any tricks to “wake” up the stages so the garmin finds it? Is it better to actually ride it while searching for the power meter?
I had to change my battery on my Stages for the second time yesterday. First time worked without a hitch so I was very disappointed when I had power readings dropping out on the way home last night. I stopped once to re-fit the battery but it still kept dropping out.
I was pretty annoyed with this as I have my biggest ride I have ever done (120miles) on Sunday and if I ever want my power meter readings recorded for posterity it’s Sunday!
I phoned up Stages and a very helpful guy said that it might be water getting in (it’s been boiling hot and bone dry here all week) and that when changing the battery the contacts can get mashed down and then don’t press against the battery as much.
I went back out to my bike and sure enough the 3 spikey contacts at the base of the battery compartment (they make contact with the middle of the battery, not the edge) were all completely flat.
I GENTLY pulled these up with my finger nail, and pulled the contact at the edge of the battery out a little and that seems to have done the trick.
I have only done a short test ride but it looks good and makes sense.
I did have a bit of trouble changing the battery this time and probably used more force that I should have done. This is probably what pushed the contacts too far down.
A lot of people on here seem to complain of issues after a battery change. Have you all tried bending the contacts back into place?
Note: You really do need to be very gentle. They are tiny bits of metal and if you break them off that’s probably a £700 paper weight.
I am going through about a battery a fortnight. Only about 5-6 rides. Certainly washing speeds it up.
I have had a battery cap replacement but they didn’t put the red o-ring in.
Things didn’t improve.
I have had two firmware updates since then and I changed the battery and swapped out the o-ring for the red one.
So new battery and o-ring as per yesterday and the latest firmware.
We’ll see how things go.
BTW connections have been easy straight forward for me. Iphone 5 or Fenx2.
BBTW The Fenix 2 doesn’t loose connection with the stages at all while being worn on my left wrist.
Wiz
Have you folks with the battery issues tried removing the battery between rides?
I installed my THIRD Stages two rides ago and it seems to work fine with my borrowed 500. With the 910xt, it had a lot of power drops when I was in the aerobars. Not sure about when I had it closer to the meter because my ANT stick isn;t working right with my computer so I couldn’t read that one. This is two rides. We’ll see how it lasts…..
BAttery will probably give out in a day or so,,,
Thanks for this extensive review. Can you recommend which Stages crank to get if I ride SRAM and have a BB30 bottom bracket? It appears they only offer SRAM Rival which is GXP. Would you advise against getting a GXP adapter for a BB30 frame or will the adapter have no impact on power measurements?
I didn’t have any plans to date, but, I also didn’t know they made a new little BLE-capable one. I’ll figure out how to order one and poke at it a bit.
Thanks, yeah I’m wondering if the new BLE Cateye is good enough to supplant a Garmin, allowing the phone to do all the heavy lifting.
Coincidentally, it looks like SRAM just announced their new Rival 22 groupset today, so you can ignore my first comment/question asking about BB30/GXP adapter…Rival 22 is going to have a BB30 option now, so presumably Stages are going to make a crank arm to go with it.
I know this was asked last year but I didn’t see an answer. Does the stages pm read accurately with osymetric rings or does it overstate the power. I noticed some sky riders are using them with the osymetrics.
Also, as I’m about to make a decision on buying either stages or power2max, are the battery issues sorted with the stages yet? How long between changes, seems to be very varied opinion.
Concerning the oval rings only power2max seems to have come clean on this (50 samples a second, weighted by angular velocity). Stages could do the same as they use an accelerometer, but since they don’t say, they are probably not doing it.
Anyone have tips when replacing batteries? I seem to go through one battery per week and will soon ask for a replacement power meter. And, this has continued to happen even with dry weather, although it seems like one torrential rain storm was the start of my problems about one month ago. Anyway, the other day the power meter did not work, and I installed a new battery. After performing the search function many times to no avail, I finally just put my old power tap wheel on the bike. Then, the next day it worked again. Seemingly no rhyme or reason to it at all.
I’ve been watching these comments regularly with great interest. I have had my Stages Ultegra crank since last September, and just am not having the same negative experiences as a lot of others. I live in Florida, and it rains every afternoon (and I seem to get caught on the bike in these 5 minute downpours), which causes no problems with my power meter. With the rain, I am forced to wash my bike pretty regularly, once again with no issues. I have replaced lots of batteries, and I mean lots, and have never had an issue. I do not have any extra protection for the battery, except for the o-ring not he battery door.
With those that are experiencing major battery issues….are you sure the batteries are good? When I started going through a bunch of batteries in January, it wasn’t the power meter killing them, it was the batteries themselves that were bad. I bought a 20 pack of Sony branded batteries from Amazon, and the first 8 died pretty quickly. I opened the remaining ones, and the voltage was less than 3.0 (sometimes as low as 2.3 volts) on each of the remaining ones. As it turns out, these Sony batteries are just old stock (and the Amazon reviews tend to bear this out). There are no date codes on any of the Sony batteries.
I started ordering Energizer batteries from another supplier that I know turns their inventory over very quickly, and have never had an issue since. A quick check in Garmin Connect shows my current battery has over 100 hours on it, and the current battery voltage is right at 2.9. I would be interested to know at what point the voltage threshold drop will no longer turn on the pod’s electronics.
The Energizer batteries have date codes on them, so you can google when they were made.
I did wonder whether it was batteries when both my power meters started working perfectly again, but then my Dura Ace one started battery draining again immediately I changed the battery. These are branded batteries (some Maxcel, some Panasonic, all with long dates and all testing at 3.2V+ when installed and coming out 24hrs later reading 2.3V).
My Dura Ace one has now decided to work again – I put a new battery in, and after 24hrs the iOS app had the battery showing yellow. I put the bike away expecting the battery to be flat the next day – but then it showed as full! I’m sending it back for a replacement anyway, but I do wonder whether batteries are the problem so I’ve just bought a batch of Duracell with long dates on them.
I have an Ultegra6800 meter, which I purchased in UK in June. First battery (supplied) lasted about 50-60 hours. The second battery went from full to yellow while the bike was sitting in the basement (vacation). I’m trying with a brand new Duracell now to rule out dodgy battery supply issues. I have the latest firmware. Interested in other’s experiences – as posted below, many happy users don’t report, so possibly it’s a few defective units rather than general problem, so I need to decide whether to push for replacement.
I did contact support, they suggested defective batteries, and to try new ones which is what I am doing now. They have been responsive, but I am concerned this might not be about the batteries. I have three other ANT devices which use the same 2032 battery type (HRM, two speed sensors) – all are still on the same battery after one year, whereas I am on the third battery now for the power meter. I also had problems with data dropouts during a long sportive (200k), which they thought could be data interference, and recommended hard coding the device ID. That was before battery died, so maybe it was related.
I’m trying to calibrate my Stages meter with my Edge 500, and while the Edge recognizes it, the Calibration screen simply says, “Calibrating…” with dashes underneath. The meter calibrates fine through the Stages app using Bluetooth.
Suggestions?
Yep, did that this afternoon. Garmin firmware is up to date too.
I’ve gone through the calibration process at least a dozen times trying the 12 o’clock position, and 6 o’clock. I even turned off the other sensors in case they were somehow interfering a, but no change. Once this morning I had 882 pop up, but it disappeared and I’ve tried to replicate it, but to no avail. I’m in touch with Stages tech support, I was just hoping that maybe someone else had the same problem.
Well, I just updated my Stages from version 2.0.51 to 2.0.58, and I am now observing the same problem as you. Stages must have broken sometthing with this update, unfortunately.
I think I’m going to start from scratch with the Garmin, setting up all of the sensors again. I was happy that I got it at least once, as it tells me the devices aren’t broken, just a communication issue.
If you’re using the meter constantly, how often do you find that you need to calibrate it?
Since it takes literally 15 seconds to do it (just answering yes to the popup on the Edge), I do it before every ride. I get pretty much the same number every time (+/- 1), so in reality it is probably just a waste to do it, but I’m an engineer, so…
Okay, I got it. I didn’t have the HR monitor out there while I was trying to calibrate before, so it was constantly searching for that while trying to deal with the Stages meter. I decided to wear the HR monitor out there this time and sure enough it was calibrated within 30sec. I had some issues with the speed/cadence sensor not picking up, but I just reset it and it is fine now.
One last question because I don’t have it in my data fields; I know the Stages meter has an accelerometer to determine cadence, but does that show up on the Edge, or do I need to put the magnet back on?
Thanks for all of your help!
Jeff, no magnet needed. Once the Stages power meter is paired up with your bike computer, the cadence reading from the power meter will take precedence over any other cadence sensor. I still keep the magnet from the Garmin GSC-10 on the crank arm because just in case the Power meter misbehaves, i can disable it and still get the cadence from GSC-10.
Your reviews are awesome, I learn a lot reading them and with this last one I think I made my mind of which Power Meter I’ll get, but I’ve got one question.
I’ve have one bike with a Dura Ace crank and another with a 105 crank (I’m planning to upgrade it to a Ultegra one) and both have the same arm distance. Will I have any problem if I get the Dura Ace Stages PM and change it from one bike to the other because of the diferent crank set?
Thank’s a lot again and keep with your great reviews.
I had the same query and contacted shimano to verify the ultegra and dur-ace crank arms had exactly the same q factor and they responded that they did so there is no issue.
Ray, any updates on this? It seems many are having issues once the first battery dies (at well under the claimed 200 hours). I got 62 hours on mine, and ever decreasing hours on successive batteries. Stages support has been less than responsive, a dramatic difference from a year ago when they were very responsive.
Hmm, I haven’t heard anything from them, but I can reach out. I would note though that most happy users generally don’t post anything – and I know that Stages continues to pump out an astounding number of units. Thus, I suspect whatever may be the case isn’t widespread but rather something to do with specific units.
Great info! I’m buying a new bike with Dura Ace and wanted to find a way to keep the Dura Ace crank and sell my Quarc. You info really helped. Great Job! Steve
I recently purchased a Stages Ultegra 6800 PM, after reading many sites, all your reviews on dcrainmaker and watching Durianriders pro Stages Youtube videos. I love the concept of the idea, the ease or installation/battery maintenance, and swap ability – I’m happy with my purchase. Phenomenal effort wight he unbiased review – awesome work!
Do you think Stages would ever consider a core refund on the left crank arms everyones taking off they’re bikes. Or offering a retrofit service to keep the cost down to budget conscious bikers?
I have just started using a Stages Power Meter with a RFLKT+. Does anyone know if the 1s, 5s, 10s smoothing options are available as I believe would be using a Garmin?
I have a Stages power meter and a Garmin 500 head unit and do a substantial amount of indoor training.
While I’m indoors on the trainer I am unable to get speed, distance information to populate. Do I need the Garmin speed, cadence sensor mounted to the bike. When I purchased the Stages meter I was told at the shop that the Garmin unit would pick it up but that I would need to disable GPS on the head unit. I disabled GPS but still do not get speed or distance reading.
If this has been mentioned before or discussed previously I regret I was not able to find any reference to it.
Unfortunately they were incorrect. Fortunately, it’s a relatively cheap fix. You’ll just need a simple speed sensor to get speed/distance indoors on a trainer. This is because the Stages has no way of knowing how fast you’re going (just power and cadence).
You’ve got a few options, though at the moment I like Garmin’s new magnet-less Speed sensor which affixes to your rear wheel. See details here: link to dcrainmaker.com
Do you think we will see any new announcements at Interbike this year? Stages really hasn’t changed much in the past 2 years and was just wondering if you think they may surprise us with something new. Thanx
Do you have any opinions on shorter intervals (ie, 5-60 sec)? Do you think the Stages is accurate in this range? Two minutes is already starting to get into the long range for non-steady state efforts.
It would really depend on a person and whether or not there was a shift in balance between higher intensities and more normalized intensities. For me, I find that at short sprint intensities my balance is quite far off, so for me it wouldn’t work as well. Others might be different.
From a pure measurement standpoint there’s no issues with sprint efforts, it does that quite well. It’s just a case of how one’s balance might shift in those shorter sprint efforts.
On one of your other post, you said that you’d put both 3s power avg & 30s power avg on your headset. How do you pace with those two values?
Do you try to put the 30s in your interval range and use the 3s to prevent extreme short bust? Or do you actually try to put the 3s average in range and just use the 30s avg as a reference as to how much power you r actually putting up?
Also, just wondering if stage power meters can be paired to two devices simultaneously? I’ve got mine paired to my garmin 500 but the Suunto Ambient 2 couldn’t find it.
For me I use the 3s as more my ‘instant power’, and then the 30s as my actual ‘here’s what I’m basically doing’ power. So I’m kinda glancing at both.
For pairing to dual, it’s just like normal since the PM doesn’t know any better. What I suspect you’re running up against is that the Suunto Ambit series is notoriously finicky when it comes to pairing any ANT+ devices. In general you need to stick the watch right next to (like rubbing) the ANT+ sensor/accessory (Stages in this case) to get initial pairing. Once that’s done you can move it back to normal range.
Just tried it and the Suunto watch found the PM successfully. Now I can utilise the free charting functions on moveslink accounts. Well, If only my Suunto does not crash that often.
Another question regarding the manual calibration 15 minutes into a ride. Do I need to do it if I’ve already done a calibration when firing up the cycling computers? What’s the rational of doing the calibration 15 mins in? Is it mainly temperature consideration (stage PM compensates for temperature variation anyway)?
Thanks again for your help and the excellent review.
I’m surprised this hasn’t been talked about much more, but why is stages only offering a one year warranty? Doesn’t make much sense to be paying 150$ to get an extra year after already spending 700$+. Every other power meter manufacturer has an industry standard of 2 years. Stages really should just offer 2 years as standard as well.
That’s an excellent question. Anecdotal tales suggest few are buying the extended warranty, and Stages is standing behind the product, even past 1 year. I took the chance and didn’t get the extended warranty and out of two PMs, one had to be replaced, the other is still going fine (6 months in).
My view: if I had a problem the refused to cover after 1 year, I would let the world know about it. And, if a product is so unreliable an extended warranty is needed, I won’t buy the product at all.
Help !!
I was seriously considering purchasing an Ultegra 6800 crank for my new madone 7. Series but the tales of battery problems really concerns me…is it worth getting one ?
Also, has anyone tried pairing these with a Bryton Rider 35 ?
Thanks.
Given the sheer volume of Stages PM’s being shipped (massive), I really think we’re probably in a case where only people with issues note it. If it was more widespread, I’d see far more comments (happy people don’t post).
That said, I did discuss it with them in person a few days ago. They noted that tracking down the earlier units with the door issue has been tough for them. They think they have them all out of the channel, but it’s trickier than they anticipated with global distribution.
They might get rid of all the negative posts on this thread if they published which serial number’s they have had problems with. Ray if you could push them to do this would be great.
I have an early one (first version did not work -second version seems fairly stable) but it is on a fair weather summer bike so I have been assuming it will likely fail at some point and thus have not bought another one for my winter bike.
To be clear, not all early ones. Rather, some specific batches where their door supplier went rouge and changed materials on them. Said supplier got Donald Trump’d.
I’ll ask at Interbike next week. Though, honestly, you’d only know once the unit showed up. And even in that case, Stages has been pretty good about swapping out for those with issues.
First you need to identify which bottom bracket you have (www.sportsmith.net/video-player.aspx?ID=a3e59e1b-6669-4036-b800-58cdce0641f0). Then you need to figure out if you can get a crank arm that fits that bottom bracket.
correct me if im wrong
i miss a part were the stages (crank power measuring ) or g3 wheel power measure is different
it like a car
you have engine HP and HP at the wheels
wheels being lower due to drive train power loss
this is the same with the bike
the crank is fairly consistent and the wheel has more variable power due to gear positions
this delta in power loss or gain will allways be there that doesnt make it worse or better power meter
Do you expect Stages to simply update their line of products with new cranks & leave all existing ones the same, or do you think they will release all new versions with improved hardware for 2015? I’m looking to buy a bike in the next month & I figure I can probably negotiate a few bucks off a power meter if I buy it at the same time as the bike, but if new hardware is coming out late this year or early next year, it may be worth waiting on the power meter to get newer technology.
I know I could just wait a week & see what actually comes out, but who has time for that!
I suspect we’ll continue to simply see them expand the available crank options. Perhaps down the road in 2015 we’ll see something, but at this point they can pretty much just keep printing money with the current offerings.
Yep. I realized my mistake a few days later when I saw that it was the information on the page that had been updated on the Sunday and not the version. Sorry about that.
I have both the Stages and power2max power meters.
Today, I discovered during an interval ride trip that they measured peak watt differently. The Stages showed 20 % more then the power2max. The are located on two different bikes, so off cause one could argument that the riding position on the stages bikes is more efficient. Has any one other than me seen that?
If they were two different bikes on two different rides/bikes, then there’s unfortunately zero valid comparison you can make there. Would need to be on the same bike on the same ride recording at the same time.
at the moment i consider to buy a stages (shimano xt) for use on a mountainbike.
how about rain/water did they finally get the thing waterproof (battery-door/cover)?
did they change something other than the o-ring in actual models?
I’ve had my Stages XT arm for about a month now. I’ve ridden it through water crossings in NC a couple of times, and have had no issues. It’s also been hosed off and bathed a couple of times with no adverse effects. I’m happy so far, and I continue to be happy with my Ultegra model as well. Two thumbs up from me.
Has anyone had issues pairing their stages with the wahoo fitness app on an iPhone 5 over bluetooth? I got mine yesterday, it works fine with the stages app and also works with trainerroad on my mac. I just cant get the wahoo fitness app to pick it up! I am sure I am doing something wrong.
I’m a long-term Stages user, and have had in total four replacements, all of which have started to drain batteries immediately after the original battery was replaced. I’ve actually been trouble free for about six months, but this weekend my Ultegra crank battery ran out, and the replacement had drained overnight.
The tab had snapped on the door, but I’m not convinced this is the issue – battery replacement seems to cause something to go haywire.
I’ve also just found that one of the tabs on the battery door on my Dura Ace crank has also snapped, so I’ve covered that with duct tape for now as I await a new one.
Both power meters have performed flawlessly since about March (c5,000 miles). Then I replaced the Ultegra battery on Saturday and by Sunday morning it was flat.
andy – thanx a lot for your reply to my question. i wait buying a stages until they managed the problems. this summer the weather here in germany was annoying enough – so i don’t need a power-meter that sucks in addition …
Love the info on the review and from everyone. Just ordered my new bike and going with the Dura Ace 9000 crank w/ Stages. I used to run a Quarc Red Line power meter. Can’t wait to try it out.
I am in the market to buy simple left crank power meter like Stage for my MTB and later Road bike for Shimano (XT and 1050. Since I started reading this great review as well as comments, I am not impressed at all with the waterproofing of Stages sensitive electronics. Also has anyone tried to put clear silicon over the battery cover or edges of stages unit? I am asking in terms of not to be constantly replacing batteries of or in the worst case replacing cranks while they are still in warranty? Also what happens after short one year warranty? Does anybody have experience with customer service and replacement of Power Meter with Stages Europe?
Since my last post regarding the “seemingly growing” number of battery issues I’ve both replaced the battery, went riding in the rain and updated the firmware via my iPhone and blue tooth connection. In short, the unit continues to work just fine. When replacing the battery, had I not watched the video on the stages website I might have been inclined to pry or otherwise break off the tab. However, if done correctly, I don’t know how anyone could break the tab off. Th battery seat is designed to push the battery up and against the tab so as to create a good seal. Unless the o ring falls out or you damage the battery area, you should not have any subsequent performance issues.
I’ve replaced the battery in several of my units several times without damaging the tabs. And on every single occasion when the original battery is replaced the new one drains overnight.
The interesting experiment I have ongoing just now is a crank I took off my bike ready to return that had definitely had a tab break, mid-ride so definite water ingress, i left it in my desk for 5 days to thoroughly dry and four weeks later it’s still fine.
I don’t think they’ve cracked this yet as they’re all red seal, new door units.
I have been using a Stages 105 Power Meter since July without issue.
Last week, my Garmin reported that the battery in the power meter was low so I replaced it. In doing so I managed to break one of the tabs on the battery cover. The cover seemed to close ok, but the next day the battery was flat. I changed again and less than 24 hours later the battery was flat again. I suspect that water may have got in, has anyone out ther managed to successfully dry one of these units out or so I have to bite the bullet and ask for a replacement?
Thank you for the quick reply. I guess broken tabs on the battery doors are not much fun with Stages on rainy days!? Hope got new door from tgh Stages cycling.
My experience is that when I opened the door it was very easy to break the tabs, and once that happens the battery discharges quickly, maybe it’s not held securely and keeps resetting or something, Stages sent me a new door, and mine has been fine since that. I dread changing the battery again. So this is not scientific but I suspect discharge problems are due to broken door tabs, not water ingress.
So: handle your door with great care, and if you break a tab, get a replacement!
The tab that broke was the main one near to where you open the cover. This has a groove on it which pulls the door in tighter, so your theory does make sense.
I contacted stages straight away and a new door is being sent out to me.
Two questions: Does any use the Stages Rival crank arm and have you changed out the batteries?
I’m reading a great deal about all these battery issues but have not seen any with regard to the model crank arm I’m using. The unit is performing well but is beginning to show “0” from time to time in the power output window on the garmin 500.
I’m wondering if this is a precursor to the initial battery needing replacement and, if so, I’m trying to prepare myself for what appear to be substantial dependability issues subsequent to changing the battery.
Thanks
Clark
For those looking at/talking about battery issues, I’d heavily stress that the sheer volume of Stages sold out there significant outnumbers those having battery issues. Except, people never come back here to say they’re happy with a device – they always come back thinking it’s a forum where they can air issues and problems.
Which isn’t to say some people aren’t running into issues – it’s just that I think those are really few and far between compared to the number of units shipped. Assuming Stages has probably shipped between 50K and 100K units (easily), a handful of people here posting issues (many of them are the same people) isn’t cause for great alarm.
Ray, you are doing great customer support and testing service for Stages and other companies. Hope they gave you something good for exchange, when you bring them great new customers. Next time you will be in town you can stop by. Prague is a great city for all the testing you do and else. Cheers from Prague.
Actually I think your assumptions of a handful of people is wrong, me and my wife have both run into problems with both of our stages power meters and have already been through 5 replacements already. It would seem after talking to the UK distributors that this a major problem hence the numerous firmware updates surrounding battery life and the issues around the Bluetooth not turning off. This is all compounded by the unit not being sealed correctly.
It’s such a shame for what could be a great power meter.
If only they had better quality control and we’re not using their customers as design testers after spending hundreds of £££££ for all this hassle.
I’d agree that these problems are relatively widespread – I don’t personally know anyone in the UK who’s bought one who *hasn’t* had problems when they replace the battery – admittedly that’s only four peopke but it’s 100% of 4,mwhich have been bought over several months. If it was only a handful of rogue units it’s pretty remarkable that so many people I meet have bought dodgy ones.
I have had seven and every single one drains batteries as soon as i replace the battery. Occasionally one will work for a few weeks, but when that battery flattens it has always had the problem again.
I don’t know how widespread this battery-draining issue is but it took two replacements to finally resolve it. My coworker bought one several months ago. His, with exactly the same battery cover and the same red O-ring as mine, was working fine, except for this one occasion when he drove through a rain storm on the interstate with his bike on the roof rack and he discovered the battery had completely drained by the following day.
we have probably seen the equipment before.
Our consultants will use their experience from many sites to ensure that
critical to quality parameters are considered during this process.
We’ve seen what works and what definitely doesn’t.
… but what i’m wondering and what is statistically impossible if there really are only few with problems is that they had the same problem 2, 3, 4 or more times after receiving new ones on exchange (unless the users that complain are fakes) …
That is an interesting experience that you guys have with Stages PM. I am glad you clarified what I was asking about. Now I am convinced that Stages is indeed great power meter and that you have to be careful when you handling battery door. Perhaps not ride while raining with broken tabs. JK. Thanks guys.
Thanks for an amazing review as always. Please do you know if the issue of carbon crank arms is now a thing of the past? Looking to order this, but would like to make sure
Stages now makes the FSA Carbon/Alloy 386 EVO Crankset PM. It includes all the bits of your drive train as well as your power meter on your left crank arm. Ray, any thoughts on whether the difference in material will effect the precision of the data?
Just wanted to chime in finally and say thank you for these extremely helpful reviews.
Also I just got off the phone with Stages and the rep said they just redesigned the battery covers which includes stronger plastics in response to the previous issues regarding battery drain (in the last month or so). The rep was very helpful and it sounds like they really stand behind their products.
Just purchased my Stages Ultegra 6800 power meter. First ride and my #’s were waaay low. Previous FTP test using virtual power from trainer road was 230w. I am a triathlete that averages 22-23mph on a 40k, but now have to struggle to hold 150-160w using the stages. Any thoughts?
Most electronic trainers, if calibrated about 10-15min in, are quite accurate. Meanwhile, comparing to Stages (which is one leg), is undoubtedly not going to be accurate.
That said, if using TrainerRoad’s Virtual Power function, then things are all over the map. Effectively you’re comparing two guesses. TR’s good if you have a method of calibrating/validating. But today they don’t yet have that for non-computerized trainers. So it fully depends on tire pressure being perfect with their power curves.
Meanwhile, Stages being left-only means it depends on you being balanced.
Stages replaced my defective 15 month old unit after the standard one year warranty was up. My battery cover was replaced last summer due to broken tabs, but I recently discovered that the interior tabs in the unit were also broken. The cover stayed on but was definitely not a water tight fit. They asked me to take pictures of the defective unit and when I took close-up pics of the interior and enlarged them on my computer I was able to see not only the broken tabs, but flaking and cracking of the interior plastic. So if you experienced broken tabs on the cover, then closely examine (with a magnifying glass) the interior to see that all is well or not.
But I can’t complain about their customer support. Next day shipping, brand new dura-ace stages crank. They even sent me a different crank length at my request. They do stand behind their product. I would buy from them again knowing I’m getting a quality power meter and great customer support.
By the way, I also have a power2max on another bike which shows that I’m 50/50 on my right/left leg power balance. I’m rarely off more than 3% on the balance during the ride and by the end of a ride it always averages to 50/50. So for me, the Stages works for me.
Garmin recommended to put the data recording from smart recording to 1 second interval. Now, I got a replacement power meter last week. The calibration of my new power meter reads approx 870>880 while the old “previous” power meter was reading calibrations values anywhere from 885>895. I do the same calibration every time. I leave the bike outdoors for 20mins before performing a calibration.
Now, it seems that the new power meter is reading watts approx 10% lower wattage than my old one.
My question is> Does changing the data recording from smart to 1 second have a drastic effect on the power meters wattage output? OR is the claim that stages make of +/-2 totally rubbish? is it more like +/-10%?
If anybody knows anything on this please help.
NOTE: i had smart recording enabled for my first power meter and now i have 1 second interval enable for my new power meter. I believe 1 second has made the power meter output a lot lower values.
The difference in calibration value shouldn’t make any difference, and the Garmins should automatically go to 1-second recording when there is a power meter connected.
You didn’t by any chance alter the zero-averaging setting? For power, the only setting that makes sense is to include zero values in the averaging (in my opinion). However, if you previously had it set to exclude zero values, then it would be expected to see a lower average wattage with zero values included.
On a related note, for cadence it is better (again, my opinion) to exclude zero values in the averaging.
Yes i have include zero values in the averaging for power. I cannot understand why the power meter is reading so low in contrast to my previous one. The battery is also perfect.
Great review and analysis. I’m still trying to understand this stuff but this certainly helps.
I have just begun looking at power meters. I used to believe that it was a Pro only training tool/device. I was wrong. It’s a great fitness tool for all.
Ray, can you post a file of your Angeles Crest ride?
I’m so impressed that you rode that, I grew up next to that highway and it’s a favorite ride. I can’t believe you rode it on a rainy drizzly day in sunny LA. It’s a classic southern California ride. A tad dangerous with traffic though.
I own a stages energy , powertap G3, and s Quarq else and my findings have my quarq and powertap dead even . When I run the stages at the same times as my powertap stages comes in at 10% higher . When riding my quarq my left right is dead even . I’ve sent files to stages and sent them my pm and they say it’s perfect but 10% is a large difference and they agree it is off compared to the other two by 10% . Plus I can tell its way off very easily.. Yet they will not refund me ..
The thing to keep in mind is that because Stages is left-only, it may indeed be actually 10% higher compared to the other two. That’s completely normal in a left-only scenario for some riders. That’s sorta the ‘risk’ to such a unit, that even if it’s measuring accurately, it won’t be giving you a complete picture of your power output.
Also, Stages measures power output at the crank arm whereas the PT measures power at the hub, post-drive train. Unless you have a 100% efficient drive-train (ie. absolutely no energy loss along the way), the Stages (or any crank, pedal or spindle based PM) will read higher than the PowerTap.
Quick question (I guess this is as good a place for it as any):
Does the calibration generally change the output of the PM, or what the headunit displays and stores?
So if the calibration discovers that currently Watts are being measured as 10W too high, does – after calibration – 1) The PM report 10W lower, or b) the headunit subtract 10W from the value recieved from the PM?
Background: If headunit A doesn’t support calibration, can I calibrate with headunit B and then ride with A?
The “calibration” is just a command to the Stages telling it to read (and internally store) the current zero value. This is then presented on the head unit, but the head unit doesn’t use it for anything.
In other words, you can do a zero reset (“calibration”) with a different device (phone or other head unit) and then use it with a headunit that doesn’t support calibration.
I’ve had my Stages power meter for 5 months now and have had an opportunity to use it with a variety of devices. I originally bought the power meter because I typically log my rides on a phone in my pocket and the Bluetooth connectivity should allow me to add power to that. I also have a couple Garmin units but I don’t always have them on my bike. I have the newest firmware and all the newest software. I’m 5’8″, 150lbs, and have tried the Stages crank on both a carbon bike and an aluminum bike. So what have I found?
1. My Nexus 5 with BTLE cannot maintain a connection with the Stages meter if it’s in my pocket. With Strava, power will go to zero any time there’s a drop and with Wahoo, power (and cadence, which doesn’t work on Strava BTLE) will slowly drop or even hold the last known value until a reconnection. Staying seated increases the chance of maintaining a connection but even on a 40 minute seated climb the connection will drop a dozen times and might even stay dropped for 5 or 10 minutes, randomly. Before I updated to Android Lollipop (5.0x, now) that had a different Bluetooth radio software, I would reconnect much more quickly and I’ve found this documented on the web by developers. I’m not going to root my phone and change radios since it didn’t work well before, either.
2. My wife’s iPhone 5 had the exact same characteristics as my Nexus 5 over bluetooth.
3. A Garmin 500 (bike) or 310XT (watch) in my jersey pocket drops data a little less often than the phones but doesn’t work well enough to justify rooting my Nexus 5 to turn on the ANT+ radio (that’s already in hardware but only supported by third party).
4. My Nexus 5 mounted on the bars and either Garmin mounted on the bars works perfectly.
5. I’ve had very cordial and useful communications with Stages about this issue but have been told that it’s well understood that the crank power meter isn’t capable of working with devices in a jersey pocket (at least for some users). There was a mention that future firmware might help but the last two revisions have made no change.
It’s a decent power meter but having BTLE and planning to use your phone is only of value if you mount your phone to the bars or you’re much more translucent to radio waves than I am. Good luck!!
Well Firmware 2.0.76 is out and it apparently solves the battery draining problem that they said was always down to water ingress (even on my brother’s two cranks, neither of which was ever used outdoors). So after more than two years it seems they’ve decided to release an update that solves a problem that they’ve consistently denied exists.
Andy, I got sent a second generation unit with the new firmware installed (warranty replacement). It’s guzzled 4 batteries in 8 days and only 2 hours of riding. I have the same firmware on an older DA9000 unit and the battery life is fine! I can’t figure it out at all!
So, I’ve had my Stages for 1.5 months and have to say that thus far, I haven’t had any issues. Now, this is my first PM and I am but a lowly non-racer who just enjoys riding the bike but I really can’t find anything to complain about…except one. A major reason for me looking at PM is that I started using a trainer (2 kids, ha!). Having the PM with TrainerRoad, Zwift, etc is so nice, gives me much more control and detailed information on my workouts. What’s a bit disappointing is the distance the Stages can actually send a signal. People have mentioned issues with having a unit/phone in the pocket and getting drops; I have to place my ANT+ USB device right next to the front wheel with an extension cable. If I just use the USB on the front of the PC forget it. Not sure why this is, maybe a battery thing (weaker signal, less power need?).
I can say that I originally was worried about water ingress and battery life but neither have cropped up. I have not tested right/left leg imbalance so I have no idea if I have a deviation but sometimes ignorance is bliss.
Matt, that’s pretty normal to need a USB extension cable for transmission. I needed one as well for my Garmin speed sensor and cadence sensor. So you’re not alone!
Ray – need a hand mate. Had a stages 7900 since the release in the states (I’m a Aussie) had one shipped over. No issues since day dot. Had it swapped due to the internal tabs breaking. Also now have a stages 6800. Have you seen and proff there are differences in the readings between models? Setup on 2 bikes same wind trainer. Output I believe there is over a 30-40 watt difference. Fluid 2 trainer, connected to zwift – pushing a 55×14 at 100 cadence only reading 270-300 watts. This can’t be right.
Something odd for the other stages owners to test and verify. We had 3 units; sold two and kept one on the rain trainer after discovering this issue. We keep getting weird moments of zero reading from the units. It seemed really random. Turn out we could reproduce it on demand. Simply ride on your stages meter and switch to 100% pulling on the pedals. In all of our bikes the power reading went to zero and stayed there until we pushed on the pedals again. That was disappointing and it would make one really question the total accuracy of the meters. So whlie we still have one stages meter we are much happier with our replacement Power2Max type S meters. Curious if anyone else can reproduce. We’re not mashers we lean heavily towards spinning high rpms so it matter alot and the power numbers we collect now make a lot more sense and match our kickr results.
Can’t say I’ve had that issue with the zeroes. On climbs I definitely pull, don’t mash, and my Stages has been fine. I’ll continue to monitor, though, and post back any changes. That is interesting.
One issue I did have was 10 minutes into a ride the Pwr on my Garmin would not even show 0 just blank, indicating the Stages cut out or powered off. Each time I would open and close the battery door then it would be ok again, usually for the ride duration. I ended up sticking a small piece of cardboard to the inside of the door thinking maybe the battery was losing contact ever so lightly. Over the past month it has been fine, no drop outs or anything.
I’m going to be moving to the Powertap pedals this fall/winter, mainly to switch between bikes easily. Will be curious to see if any discrepancies show up; I like the Stages but have nothing to compare it to.
Bob, what do you mean by “switch to 100% pulling on the pedals”? How are you accomplishing this? If you are standing off the saddle, this could be a connectivity issue with the head unit. I had a unit that would drop power data when I stood on the bike due to a weak signal. In my case, replacing the unit was the only solution.
Sorry let me clarify. Sit on the saddle, and only lift the pedals with your shoes by pulling up; don’t push down on them; down stroke is a dead leg doing nothing. We noticed doing drills on hill repeats as we were working on our upstrokes. Still not sure why the strain gauges don’t record anything. This was down with Rival Arms 165mm; I have no examples for other arms.
That is very interesting. I’ve never had this particular issue. I have ridden on the trainer concentrating on the pull stroke when I was recovering from a strained knee – can’t say it was 100% up stroke – but I found the stages consistent with my effort output. I found the Stages to be very sensitive (and accurate?) when I consciously change any effort on the left leg – pulling up or mashing down. Stages has been very good to me fixing issues like power drops and inconsistent data even after my warranty had passed. Despite some product production / software issues, they do stand behind their product.
I’m very encouraged to read that after all the software updated you would recommend the Stages power meter as much as other power meters. In my particular case I already own a Power2Max power meter, which I love, and I’m currently considering to purchase a Stages power meter for my new bike. However I’m a little bit struggling over performance of the Stages vs P2M and the additional investment. (Sorry if my comment is not purely related to Stages).
I have a P2M Type S power meter with Rotor 3D cranks and 50-34 chainrings on my old road bike.
My new bike came with a full Ultegra Di2 group and 52-36 chainrings. My plan was to swap the cranks and use the P2M on the new bike.
However now I’m concerned to use the Rotor 3D with P2M on the new bike due to the following
– Performance of non-Shimano cranks with Di2
– Different chain rings required Di2 adjustment, but I hate to mess with my new bike
Hence, my idea to install a Ultegra Stages PM instead and keep the new bike as much untouched as possible. However then I’m wondering how much different the performance is between Stages in P2M. From the P2M I know my left-right ratio is usually between 50% and 52% (left).
I too have a p2m on my main road bike. I know my left-right power ratio which is 49/51 when I’m going full gas, but generally 50/50 on all other efforts. Therefore, I’m satisfied with the stages to meet my needs for a pwr meter for my other bikes. Their customer support is excellent. I just had another issue and they sent me another replacement for a Stages that I originally purchased in 2013. And I did not purchase the extra accidental warranty. This is the third one they have replaced, but I’m fairly confident that they are correcting the problems I’ve had in the past, i.e. they will have a new design “in a matter of weeks” available. This recent replacement has a new housing design and I think they have addressed the problems they had with the old design (mainly to do with the battery cover and engagement latches). My Stages pm (I only have one) is so easily interchangeable, that if you want to use it on multiple bikes with compatible cranksets or don’t want to replace the crankset, this is the way to go.
As a follow up to answer your how Stages compare with P2M, I don’t know. I don’t think there are any problems with either as they are initially calibrated at production, and both are user calibrated, and compensate for temperature changes. I have not detected any power output readings that are off. But then again, I have no idea when my legs are on or off given a particular ride. I am very satisfied with my P2M. The P2M I installed last year and it has been install and forget it – it just works. But having said that, I will be buying another Stages soon (when the new housing is available) for my new cross bike.
I have 2 stages power meters and both have failed in the last month. They are less than 1 year old.
It starts with battery drainage, then dropping data, then complete failure of the strain gauges.
Once I get them back from warranty repair I am going to use them as paperweights or kitchen utensils.
I have 2 other meters from power tap(g3 hubs) which have performed flawlessly for 3 years.
I would not recommend anyone purchase a stages power meter.
They made a pretty big change back in September to address the battery drainage issue due to the waterproofing of the case. Details here: link to dcrainmaker.com
I’m not sure if the 2nd generation models will be any different in terms of reliability. Another one just quit working tonight. This will be the 5th replacement (and two have been for the 2nd gen models). And I don’t ever ride in the rain!
First one was for broken internal tabs for the battery door. Second was for data drops / weak signal. 3rd was for more broken tabs (brittle plastic). 4th was a 2nd generation model that had me believing that I should turn pro and ever increasing calibration numbers from 820 to 1004. The latest is also a 2nd generation that had a jump in calibration numbers and then just quit working.
These problems have nothing to do with how these power meters are used (I am meticulously careful with my cycling gear) – it is poor quality control. I love the Stages when they are working, but this is getting old…has been for awhile now.
I purchased a 2nd gen in September hoping for smooth sailing but aside from the obvious cosmetic change in the pod, my experience has been similar to troubled 1st gen users. With the 105 arm and a Garmin 510, I get one or two dropouts every 30 min or so which isn’t a big deal. But the main issue has been battery drainage. I’ve gone through 6 batteries now in 2 weeks… at less than a total of 5 hours ride time.
I’ve checked the cover, o-ring, and tried the paper technique while checking the tabs and I can’t figure it out. Batteries are dying in a couple of days. Folks at Stages have been pretty eager to help and resolve the issue, so I’m grateful for that. Waiting on new battery covers and o-rings now.
I have also had power drops and battery draining issues in separate units (generation 1). The power drop issue took 30 email exchanges to convince them that my unit was defective (that really tried my patience), but then the replacement worked perfectly… until the internal latch tabs broke when I was changing out the battery, and they actually convinced me to have it replaced. Should have kept that one since it worked and was only going to be used on the trainer. Now, I’m still looking for a replacement that works.
Just wanted to follow up on my post here. They ended up sending the o-rings and battery doors for the first generation by mistake, so I notified them immediately and they decided to next day a replacement arm instead for the hassle. Dropped the old arm in the postage paid box for return, mounted the replacement arm… zero problems since. I’m now at about two weeks with a handful of rides and battery reads full and haven’t had any problems with connection on the 510 or 520. Time will tell of course!
I’ve seen a smattering of people having to go through multiple power meters until they get one that works – here and at other forums. I for one will probably see a 5th replacement unless their support comes up with a miracle cure. I find it hard to believe that they can sustain this kind of business model unless they are taking big shortcuts on their production costs. Am I an exception? No, I was never the lucky one to win the lottery nor was I one to always get the short end of the straw. I’m beginning to sense from my experience with them over 2 years that the customer support folks are under pressure to “resolve” these issues with customers before issuing a replacement. I have had over 60 emails exchanges and multiple phone calls, and most of them has me defending myself that I am not doing something wrong with their product. I have tried my best in tolerating their patronizing tone. Their power meter cranks are installed in minutes, but imagine if you had to replace a hub power meter (or a crankset power meter with handpicked chain rings or devices that required a significant setup time) over and over. Would customers tolerate that? From my earlier comments on this forum, I fully supported them, but now I am about to turn the corner… if I haven’t yet.
I have had my 105 STAGES since August 2014. Until Sep 2015 it was fine, then it started dropping out on power but i noticed it was on rough bumpy ground only, the Edge 1000 would beep saying STAGES lost / detected. Inspecting the battery cover, i saw the tabs were broken, contacting STAGES, they sent me some new ones with new o rings immediately, no issue. Installed, still power dropped out. Inspecting again, i noticed one of the copper / gold plated three legs on the PCB battery terminal had broken off see picture, i contacted STAGES, they asked questions blah blah blah. After several emails, i took matters into my own hands, sticking a small 4mm square felt tape pad on the inside of the door in the hope it would stop what i had guess to be the CR2032 rattling around in there. Hey presto, no issues now since 1000km of riding. Gave up contacting STAGES since it works fine…….for now anyway. I am, have been and still am happy with it, it works now at least. Maybe worth a try for some?
I used the new version of the Stages PM today for my indoor roller ride. I use it with a Garmin 510 head unit. It appears that when I’m stopped, the power continues to be accounted for, thus bringing down the avg power and other metrics. What is the fix for this? Does mashing the stop button on the head unit resolve the problem? Or, setting the unit to not count zeros? Please advise, thank you.
I was sent a second generation unit as a replacement for an first generation which died after 8 months. The second generation unit has consumed 4 batteries in 8 days (and only 2 hours of riding)! It’s going back today!
The battery door does seem a lot more substantial on the new unit though.
I wish someone from Stages would come on here and explain exactly what is causing the rapid battery drainage problem even in second generation units.
I bought DA9000 Stages in April 2014 for my fair weather bike, which has been faultless apart from needing a new battery cover almost every time it needs a new battery.
Based on this experience I then bought an Ultegra 6800 unit for my wet / winter bike in February 2015. In November this year, while wiping the bike down after a ride, I noticed that the battery compartment had partially popped open. When I removed the door, sure enough two of the three tabs had spontaneously snapped off, and water had got in. The service from Stages UK distributor (Saddleback) & Merlin was excellent, and I had a new second generation unit within a week. I had high hopes for this in view of the new design. Unfortunately that was’t to be the case, and this unit consumed 4 batteries in 8 days with only a couple of hours of riding!
Previously this has been attributed to poorly fitting battery doors / water penetration, but that was supposedly fixed with the redesigned casing of the second generation units. Furthermore, this unit had never seen a drop of moisture.
The batteries were from 3 different reputable brands, & batteries from the same sources have been happily powering other devices including my other Stages first generation unit, so it’s obviously not the batteries at fault.
I wondered if the faulty unit was not “going to sleep” when not in use and hence consuming more power. So I would sneak up on it when the bike wasn’t in use, with the Stages app running on my iPhone to see if it was broadcasting when it should be asleep, but that certainly wasn’t the case.
I can only conclude that there is some fundamental flaw in the electronics, which Stages clearly still don’t have a handle, on as my replacement second generation unit was afflicted with exactly the same fault some first generation users described years ago. This is such a shame. For me it was almost the ideal power meter, as I wanted to stick with my Shimano crank / chainrings / SPD-SL pedals and Mavic Exalith wheels. Plus, having the device as part of a component with no moving parts (the left hand crank) made me feel it should be more robust than some of the alternatives.
Merlin kindly gave me a full refund when I returned the second generation unit. I’m now thinking about switching over to Powertap P1 pedals, but the less stable nature of the xpedo pedal / cleat interface makes me want to stick with SPD-SL.
If I though Stages had any kind of handle on what the problem is I might be inclined to give them a third chance!
Hi ! first – thanks for amazing site, first post, but I read it all the time !! Can’t find an answer: would a Dura-ace stage crank on an Ultegra set bike ? is there an issue with Dura-ace left and ultegra right ? thx !
I initially was posting under the Garmin 520 section but feel now its more appropriate to post here, under Stages PM. I purchased the new carbon Stages crank for Red 22 BB30 but was having power drop out problems with my Garmin Edge 500. I was using the SRAM Garmin mount (in front of bar) like I always used pre-power meter. My buddy got the Edge 520 with his Stages PM and it worked fine, so I decided to try it. My Edge 520 that I got was also having drop out problems, in fact much worse than the 500, so I decided to do some rides with the 500 and 520 both paired to the Stages. Turns out which ever head unit was in the “out front” mount (in front of bar) would drop out frequently and which ever was in the stem mount holder never dropped out. So is the handle bar blocking the Signal? Is the Stages signal a weaker ANT signal than other power meters that rarely, if ever drop out? It seems that its a Stages problem as opposed to Garmin but Stages refuses to admit that, putting the blame on Garmin. Yes, I could just use the stem mount and not have many, if any drop outs. But why wouldn’t this be something that should be addressed by Stages if so many users of Stages have this problem? Thoughts Ray, or anyone? Pretty frustrating!
I’ve been through a few defective Stages PMs. One was a unit that would constantly drop the signal. I did multiple tests accounting for interference from other devices, placement of my garmins, battery changes, etc… The only way to eliminate drops was to mount the garmin on my seat post. And the only thing that resolved the problem was a replacement unit. Once I got the replacement – no problems. Dealing with Stages was a huge headache. They would not admit that the unit would have that kind of defect. I’ve said this before, they have poor quality control.
Its weird because I’ve heard so many good stories about Stages customer service too. So far thats not the case for me. They are basically blaming Garmin and not taking the blame themselves. I tried 4 different Garmins so far and they ALL drop out! 2 Gamins are mine, one from buddy who has a Pioneer PM, and one from a buddy who has P1’s. Their power meters NEVER drop out with the 2 Garmins I tried. You should not have to mount it to your seatpost, top tube or whatever. If a head unit is 3 feet away and all that “slightly” blocks it is a narrow handlebar, theres something wrong! I have a feeling Stages is going to string me along on this for a while until after my warranty is up. They refuse to send me a new one…so far.
I had a similar issue with a G2 unit. After a couple of weeks working correctly, I started to get major connectivity problems on ANT + – basically the unit had to be within 50 cm to pick up properly. Interestingly the BLE signal was fine.
Stages replaced the unit and it now works fine however the Ant+ signal is WAY weaker than the BLE signal, and also much weaker than the signal from my Powertap G3 hub, so the signal strength may still cause issues.
I have found the support to be very good, but I also have the impression that they may still have a couple of design and or quality issues even with the G2 units.
I couldn’t agree more. After reading many forums and talking to friends with stages and other PM’s, it seems obvious that the stages ant signal is weaker than most other PM signals. It also seems some stages have stronger signals than others. I rode with a buddy yesterday with stages and he held my Garmin and I held his and we started very slowly riding apart from each other. This was for me to let him know when his dropped out and vice versa. My power dropped out around 5′ and his didn’t drop out until he was about 20′ from me. We did this 4 times and every time the same thing. Its simple, my stages is putting out a weak signal, but so far stages won’t budge. For right now, I’m not liking stages customer service very much!
Hi! The same thing happens to me. I’m using Stages (2nd generation) with Garmin Edge 500 and have constant connection drop outs when the Edge is on the barfly mount (insomuch that Stages will go to the “sleep” mode).
When the Edge is on the stem it seems the handlebar is not blocking the way to ANT+ signal and the drop outs occur but not so often. I also blame the weak signal of the transmitter on the Stages.
I’ve tried replacing battery, manually pairing the Stages with the Edge, removing and unpairing all other ANT+ devices, hard-resetting the Edge, – nothing helped.
The only case when the connection is reliable is when I’m on my turbo trainer and the ANT stick (connected via usb extension cable) is placed on the floor 30cm from the crankarm.
Hi Konstantin – Yes it was really annoying for me. Since my post Stages finally (took a long time!) sent me a new crank. I used it several times with my Edge 520 on the bar mount and it has been working great. I even had my friend hold it while we were riding and slowly rode away from him until it dropped out, which was approx. 5 meters away…not too bad. My last PM would drop out at about 1 1/2 – 2 meters. The only thing I’m concerned with now is that during a mountain trip a couple days ago (I brought my older Edge 500 because I was going to do some mtn biking as well) it dropped out several times. Not sure if this was due to using the older 500, or being in the mountains with dense forests or…? Im back home now and will be testing it out again with my 520. Fingers are crossed!
But to me there is no question that there is a weak signal with Stages PM in many cases!
Opened the support ticket – will see what they think on the issue.
Have you by chance tried Bluetooth connection on the 520 instead of ant+? I wonder if it improves the situation significantly
I’ve had my Stages Gen2 for about 5 weeks now and it is terrible. Using the .fit file repair tool I’ve found that when mounted out front the reception between my head unit and the Stages is about 37% which leads to CONSTANT drop outs, so bad the PM is almost unuseable.
Stem mounted resolves the issue but this is not acceptable to me.
Same here, I just purchased a stages PM 2nd gen and I’m having lots of drop outs….
My head unit is a garmin 1000, and analysing with fit file repair, when mounted out front the reception between my head unit and the Stages is about 30-35%, which means in practical terms 2-3 dropouts per minute, unusable.
When mounted on the stem, the reception improves a lot, up to 73-77%, but this is not good enough, as you still get 5-10 dropouts per hour, better, but still annoying and not good enough to get the right power averages (and not good, since I like more the out front mount)
Any advise? should I push for a replacement? the PM is just 2 weeks old
Got the answer from Stages support then (first they asked me to provide the photos of the power meter and head-unit location on a bike):
“…Looking at those photos your power meter is in really good condition, so I do think the dropout issue you have been seeing is more likely related to the location of your 500.
We have seen a similar issue with the 520, although potentially caused by a different issue with the new 520 ANT+ chip stack. The 510/810 have been the most reliable in our experience, but the former has since been discontinued by Garmin…
…For the time being, having the 500 mounted on the stem, or looking into the 810 option from Garmin would be the course of action I would recommend. Because the stem mount does not show the same activity, I think the issue more likely lies with the orientation of the receiver there, rather than the power meter itself…”
As you may have read I have had many issues with my Stages 2nd gen/Garmin 520 set up. I’m still not exactly sure who’s fault it is…possibly both. I see Konstantin your remark from Garmin about the 520 ANT+ chip stack, which doesn’t surprise me. Though I also feel the Stages puts out a bit weaker signal than some other companies for whatever reason. And BTW I used my buddies Garmin 810 on a few rides along side my 520, while alternating them back and forth from stem to out front mount, and the 810 never dropped out while my 520 had its normal dropouts, so…
Also, I am on my 3rd Garmin 520 as well as my 3rd Stages 2nd gen (though the 3rd time I sent back the crank arm and they just replaced the internals). Knock on wood and I’m happy to say I have not seen one drop out in my 10 or so rides yet. Man I hope I just didn’t jinx myself though!!
Has anyone else had an issue when trying to update the firmware. Iphone app is connected to the PM yet when trying to update the firmware the screen shows status at 0% and then just hangs at that percentage and does not actually complete any update. Go back to the home screen and the app is still connected to the PM so no issues there. Brand new battery in the PM and phone fully charged. Extremely annoying.
Very in depth review, as always i enjoyed very much.
I wanted to install the stages powermeter (dura ace on my ultegra crank arm). However that was not possible since the powermeter comes into contact with my ultegra break, which sits under the bike. Anybody had the same problem and maybe a solution?
You might want to reach out to Stages to see if they have specific frame recommendations. Most PM companies can tell you which exact unit will work. Unfortunately, if it’s hitting, there’s very little you’ll be able to do aside from swapping out for a different unit (if that).
I updated my firmware a week ago (on Tuesday 19th April) to version v2.0.79 and I seem to have issues with batteries draining very quickly.
The first battery that I replaced at the same time that I updated last a week (180 miles) and the battery that I put in yesterday was dead this morning.
Well, I say dead but I don’t actually know if it was. The power meter refused to wake up and connect to my garmin. When I put a new battery in in woke up and connected straight away.
I am following thsi link for a while now, i’d like to post my thoughts and i think my solution. My Stages 105 i have had now for 2 years, about a year ago it also started playing up intermitently loosing / cutting power readings so i contacted Stages who sent me x2 new covers and new red o’rings. Fitted them, all was ok for about 50km then started again. Taking a closer look, i saw the x3 gold plated battery prongs on teh pcbs, one was missing and they looked flattened so i bent one up then on the inside of the battery cover fitted a small square of thin felt tape. Now ive covered at least 3000km or more, no issues! I believe the intermitent cutting out is caused by the PCB prongs and the battery rattling around inside the battery cover. Give it a try, it might just work for you but i know we shouldnt be doing this but worht a go and at least the tape you can remove if you wish to return it. Good luck.
Thorough test, thanks! Does Stages power meter also measure the upstroke (of the left leg, I suppose, and then double it)? Does it perhaps measure the entire stroke/rotation of the left leg?
Does anyone know the effect of not zeroing a Stages before a ride? Does it result in higher or lower power numbers? If there is little to no effect then i’ll stop doing it for every ride!
Hi Lewis – I always calibrate before every ride and try to get the calibration around 900. I have found straying more than 7 (calibrate between 893-907) in either direction results in drastically higher or lower power numbers. I can usually tell by my effort and HR where I should be on power and have found that calibration range to be most accurate for me. Sometimes a pain getting it there when you are in a hurry to ride but worth it for the data consistency.
There is no such thing as “trying to get the calibration value within some range”. Calibration is done with the arm vertical, and that’s it. You get the value you get, and it will vary a little due to temperature changes and it can also shift a little as the meter is ageing.
As long as the value is between 840 and 940, and hasn’t jumped drastically since the last calibration, you should be good to go. Here’s what Stages says:
I always do a calibration (which is not really a calibration, in the true sense of the word) before each ride, because even if it might not be necessary, it takes literally just 10-15 seconds of my time.
I zero/calibrate my Stages PM before 95% of my rides, but sometimes on a commute home i don’t bother. I have never seen any numbers or load scores that seem out of the ordinary. I don’t have any reason to believe that it makes a huge difference to the power data.
I am yet to find any information out there that can tell me what is the actual effect on the power data. I would love to know. Might be a question for the Stages support team?
Zero offsets in the cases of Stages are mostly useful for identifying when something is going horribly wrong. Stages automatically compensates for temperature differences, so the zero offset is more of a formality and quick validation than anything else in their case.
That said, it’s useful to do prior to a ride, as if it comes back with a wonky result, you’ll know then rather than during the ride or afterwards.
My unit is just over a year old, well more like 18 months now and i’m having huge issues with it that started back in July.
It had worked faultlessly until that point, fit and forget. On that ride, all was normal and then my head unit (Edge810) stopped receiving cadence and power data. Odd, i thought, but i suspected a battery seeing as i hadn’t ever replaced it.
Went to change it and the door just came away in my hand, the lugs were broken. Spoke to Stages and they sent me out a couple of doors and new seals.
Since then however, i’m having huge problems connecting to the unit. To the point where i now just give up and ride. My Edge just can’t find the Stages. Sometimes it will find it if i hold it right next to it, but it doesn’t even seem to do that anymore.
I did a ride today and paired my Forerunner 920 with the Stages as well last week (as a back up). Neither unit could connect this morning so i just went for a ride. During the ride, when i looked back at the data, the 920 was receiving data from the Stages for a little bit. Then it dropped off and then came back again. I also got a ‘Power Meter Low Battery’ warning at the end of my ride. The battery was brand new this morning (in an attempt to get a connection).
Any thoughts as it’s become a real pain. 75% of my training is power based and i’m on the verge of going and buying an alternative solution.
I’m having the same issue with mine to the point I’m ready to just buy a new unit as well. I called Stages and they sent me a new door and seals just like you. I got it to work but continued to have the same issues with the cadence and power readings continuing dropping out. I called them back and they basically said they’ve had issues with Garmin products and the unit needs to be as close to the Garmin as possible. I have the 920xt as well and I expressed my disbelief that they would create a product that is essentially incompatible with the leading multi sport watch brand in the market. I’m paraphrasing here but tough luck was essentially the response I got. I understand they are the “value” version in the power meter market but $750 is not a drop in the bucket. Extremely frustrating.
In “studies of how people peddle:” you wrote “Keep in mind that it’s last year that we finally got a left/right power meter that works outdoors”. I realize that this article is over three years old now, but I wanted to point out that the Polar Power Output sensor was available in 2001. It did in fact offer left/right pedaling analysis in the form of l/r percentage and circular distribution (they called it ‘pedaling index’). It wasn’t a real power reading but I suppose one could have extrapolated power. FWIW, comparisons against a computrainer were pretty good, never varying more than 5% for peak and interval measurement, and pretty damned close for average ride readings.
I used it for about 5 years starting in 2005, until I got hit from behind on a group ride which tore off the chain speed sensor that attaches to the lower jockey wheel. The thing was a total PIA to set up – both mechanically and programming – and I had an issue with the battery only lasting about a week. While futzing with to see why the battery kept dying, I discovered the 3 pin connector inside the handle bar mount had the power and return pins ever-so-slightly shorted. After I fixed that I quite literally had trouble-free seasons with it. until the crash.
BTW – this article is great. I’m an EE, love the scientific approach and report.
Hey, so question on your comparison plots: from the titles, one would assume that you are showing Quark-Stages, Powertap-Stages and Powertap-Quark (lets use these three… and those are minus signs). When I look at those I see a pretty interesting trend: Q-S shows that the Quark is giving you 10W more power during your actual power on intervals (likely due to the fact that when your left leg fatigues and you subconsciously switch, it reads it), P-S shows the opposite, which again makes sense as the Powertap is at the end of the powertrain, so you’re subtracting off higher watts from the one legged “crank horsepower” if you will, which causes the negative numbers, and the final P-Q which shows a net-zero effect. What I’d like to know is, what is that effective “left-leggedness”? is there a correction factor that could be calculated per-person… for instance, riding on rollers with a powertap and a stages, I could develop a correction curve, which would in effect map out that fatigue… but that would be different on any given day, and any given level of fatigue or alertness (extra strong coffee)…. so really… it’s not as accurate a power meter… the variance shown there is substantial, even if your NP’s show to be within an acceptable tolerance, your NP per interval is not (by the looks of things anyhow…).
I only bring this up as I have been using stages for training myself for a couple seasons, and have been very irritated by the one legged situation (as all one legged power meters would be). Outside I find that the power meter performs quite well, though this likely due to the lack of control of variation and continuous variation at that. Indoors with set intervals, I find that the power is quite mis-representing and under-represents your output due to all of the controlled variables and being able to mentally focus on which leg puts out more power…
Anyway, I haven’t read your previous version and I noticed the preamble on “you’re doing it wrong” with regards to pedal efficiency and bias… just curious as to what your thoughts were on those 10-20 watt variances. Otherwise, as always you have an exceptional blog!
I know that this is a very old post now but I thought that this was probably the best place to ask you a question.
I have an Edge 1000, several Virb cameras and a stages power meter. I have a Virb on my handlebars so that I can see it’s display.
Fairly often when I look down at my Edge the power reading is nothing (– as opposed to 0) – this can last several seconds, possibly up to around 10 – 15. This is when I am pedaling and is not after I have just re-started so there should be power displayed and sure enough on the Virb screen I can see power.
I thought that maybe the Edge was dropping out and not getting these values so for one ride I compared the data from the Edge to data from the Virb by uploading them both to Strava. I was expecting the kilojoules of the edge to be lower due to it’s drop outs but the values were basically the same and in fact the edge was ever so slightly higher.
It seems to me that for some reason the Edge is receiving data but not displaying it. The field I use is instant power, no averaging.
I suspected that this was a problem with the Edge so I paid for a replacement from Garmin outside of my warranty period but this had no effect on the issue.
I saw that on another post you mentioned that drop outs from Stages were not unheard of so I thought it was worth asking.
That’s definitely odd. Usually the drops are drops – meaning, they definitely show up in the file. One thing to double-check though is whether Strava or GC is ‘faking’ the missing data. GC does this by just pretending they weren’t drops and marking them null. I don’t remember off-hand if Strava does. You could use the DCR Analyzer to double-check too.*
If you want, shoot me two files and I’d be happy to do a quick overlay for you to see what the Analyzer shows. I know you’ve been a longtime DCR Supporter – I appreciate it! Just ray at the domain.
Also, I presume you’ve updated your Stages power meter firmware too. There was an update last April that helps out a fair bit here.
Within the last couple months my Garmin 520 has also been unable to get good data from my stages power meter. I had very few issues until recently. I sent my power meter back and they couldn’t find any issues with it. I find a ton of zeroes when I’m pedaling. Garmin claims it’s the low ant+ broadcast from the stages meter. I feel like maybe Garmin changed their OS and this has affected my data immensely.
I bought a stages power meter way back in 2014 but as I have recently crashed my bike and got an insurance pay out I am moving to a Quark.
Stages support have been brilliant. Despite only paying for a power meter in 2014 I think I have probably had about 5 brand new power meters from them for all 3 generations.
The first generation suffered from water issues. I was sent new doors and seals but eventually they replaced it with a Gen 2.
I can’t remember what issues the Gen 2 units I had were. Possibly water or possibly accuracy…
The Gen 3 unit had very odd accuracy issues and was replaced when I had it for only a few months.
As I said I am very happy with the customer support but it seems that this far into a product’s life they should have ironed out these recurring issues.
Now that I have an opportunity to move to something else I hope that the Quark will be as accurate and resilient as Ray implies it is.
the best customer service is making products that don’t require customer service. IME stages fails miserably on that metric. Between my road and MTB, I have had 3 devices on one and 2 on the other. They seem to finally have gotten it right. Their early product claims were pretty much fictional. Stuff like 200 hours of battery life when I was seeing maybe 30.
I purchased the original gen 1. It developed the well known crack in the plastic housing as well as the battery door failing initially.
Whilst the customer service team are prompt and polite there will be a lot of people like myself whom committed to the first gen paying a lot more than they retail now for a product not fit for he market.
Unfortunately out of warranty in the UK you just get a discount of 30% on a new unit (gen 3).
In my case it never saw rain with the bike stored indoors and only a 1000 miles done on the bike.
Not what I’d call value for money. So if i purchased the new gen 3 my total outlay for a left sided power meter only would be over £1000!
If and when I do get another power meter thinking of 4iii as have heard better things and it’s cheaper than the stages even with the discount!
If your looking at a power meter I would recommend looking at known faults and issues with all companies. As mine was a gen 1 this wasn’t available at the time of purchase.
I had similar experiences with a gen 1 on my mtb and another on my cross bike. Between the two, I am on my 4th and 5th pm from stages at this point. Stages 1st gen products have been without a doubt the most troublesome cycling product I’ve ever purchased. Having to pay to for upgrades to newer models when the older ones were clearly not ready for the release just adds insult.
Really appreciate your thorough testing and reviewing of equipment. As a Stages 3 power meter user, this update is gratifying and helpful as I adapt to the power meter world. So, thank you.
Buy a Stages XT Gen 2 left crank and make a Lama Test Lab like GPlama does and I get a 20w-25w difference all the workout. The Stages as lower watts than my Tacx Flux S.
Is this normal?
The calibration value is only 869
I swim, bike and run. Then, I come here and write about my adventures. It’s as simple as that. Most of the time. If you’re new around these parts, here’s the long version of my story.
You'll support the site, and get ad-free DCR! Plus, you'll be more awesome. Click above for all the details. Oh, and you can sign-up for the newsletter here!
Here’s how to save!
Wanna save some cash and support the site? These companies help support the site! With Backcountry.com or Competitive Cyclist with either the coupon code DCRAINMAKER for first time users saving 15% on applicable products.
You can also pick-up tons of gear at REI via these links, which is a long-time supporter as well:
Alternatively, for everything else on the planet, simply buy your goods from Amazon via the link below and I get a tiny bit back as an Amazon Associate. No cost to you, easy as pie!
You can use the above link for any Amazon country and it (should) automatically redirect to your local Amazon site.
While I don't partner with many companies, there's a few that I love, and support the site. Full details!
Want to compare the features of each product, down to the nitty-gritty? No problem, the product comparison data is constantly updated with new products and new features added to old products!
Wanna create comparison chart graphs just like I do for GPS, heart rate, power meters and more? No problem, here's the platform I use - you can too!
Think my written reviews are deep? You should check out my videos. I take things to a whole new level of interactive depth!
Smart Trainers Buyers Guide: Looking at a smart trainer this winter? I cover all the units to buy (and avoid) for indoor training. The good, the bad, and the ugly.
Check out
my weekly podcast - with DesFit, which is packed with both gadget and non-gadget goodness!
Get all your awesome DC Rainmaker gear here!
FAQ’s
I have built an extensive list of my most frequently asked questions. Below are the most popular.
You probably stumbled upon here looking for a review of a sports gadget. If you’re trying to decide which unit to buy – check out my in-depth reviews section. Some reviews are over 60 pages long when printed out, with hundreds of photos! I aim to leave no stone unturned.
I travel a fair bit, both for work and for fun. Here’s a bunch of random trip reports and daily trip-logs that I’ve put together and posted. I’ve sorted it all by world geography, in an attempt to make it easy to figure out where I’ve been.
The most common question I receive outside of the “what’s the best GPS watch for me” variant, are photography-esq based. So in efforts to combat the amount of emails I need to sort through on a daily basis, I’ve complied this “My Photography Gear” post for your curious minds (including drones & action cams!)! It’s a nice break from the day-to-day sports-tech talk, and I hope you get something out of it!
Many readers stumble into my website in search of information on the latest and greatest sports tech products. But at the end of the day, you might just be wondering “What does Ray use when not testing new products?”. So here is the most up to date list of products I like and fit the bill for me and my training needs best! DC Rainmaker 2024 swim, bike, run, and general gear list. But wait, are you a female and feel like these things might not apply to you? If that’s the case (but certainly not saying my choices aren’t good for women), and you just want to see a different gear junkies “picks”, check out The Girl’s Gear Guide too.

































































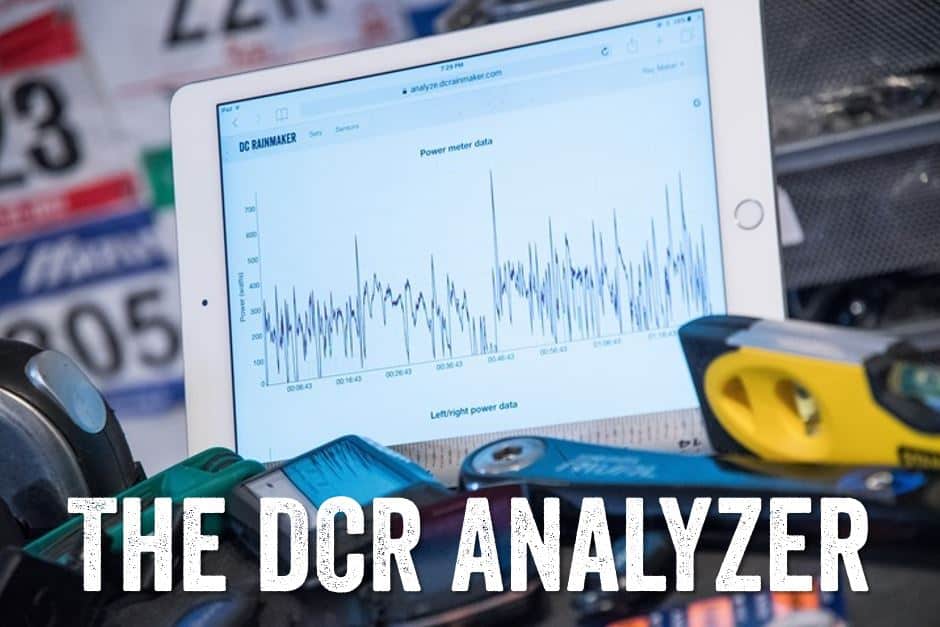








Just to make a pause on battery drainage (hopefully to be resolved on the near future…..).
Does anybody know how to interpret the new data: pedal smoothness and torque effectiveness? Both data shows two percentages (obviously, there are not one for each leg)….so what do these data mean? Any clue?
Thanks.
Here is food for thought on battery drainage. I am not saying this problem solves for all because there seems to be some real legit issues with moisture. I do not own a Stages unit and I am here trying to decide.
That being said I have a Garmin 500 and have noticed that I can go for a ride come back home take it off the bike and whether I plug it in or hook it to my computer it will stay in the on mode unless I specifically shut the power down. That being the case whether my bike was in the garage or in the house it would stay paired to something like the Stages unit until I specifically shut it down. I know I have friends who come in for a ride plug their Garmin type unit in and may not be able to ride for days but the unit stays on and even when you shut it off and plug it into power or computer they auto turn on.(the issue is probably more likely with the Bluetooth than the Antenna + but is possible for both) Well the math is easy 24 hour days on for three to four days. The battery drain would be more severe as well as constantly on for days straight compared to on and off after 2 to 6 hour rides so the 200 hours would go out the window as constant drain is different than on and off.
Again just food for thought and maybe it will help some.
I think this was actually an issue to begin with, but Stages released a firmware update that was intended to fix it.
I guess it may still be an issue though – who knows!
As John says pre-2.0.37 software they thought that was the main issue – but that didn’t stop mine draining batteries for fun. My latest one has arrived and fitted – so we’ll see how we go this time!
Latest instalment:
Nice bloke from Stages is sending another replacement via Saddleback. I email SB to ask them to let me know when it arrives. Today, I get an email from them asking why I’ve been dealing with Stages direct and asking me for a whole load of info about the problem, what the serial number is, why I got a replacement direct from Stages (erm…because they said they’d send me one…) and generally making me feel like I’d been a naughty boy. They also told me that “according to their records” my cranks both came from Sigma sport. Nope – neither of them did.
Anyway – their email says when they’ve got the info they’ll “decide on the best course of action” – which is worrying as I’ve heard that they’ve tried to wriggle out of things by saying it’s “not a warranty issue” (which is a massive contrast to Stages, who sent me a replacement without me needing to return the one I had).
I’ve told them I don’t want them to “decide on the best course of action” – I just want my new crank!
We’ll see…
That doesn’t sound good… I think SB have dispatched mine today, so I’m ok if this one works fine! Perhaps I’ll go for the duct tape solution mentioned above as a precaution!
Hi John – how’s the new power meter? My new one arrived today, so fingers crossed!
Hi Andy. Got mine at the beginning of the week. Only been out a couple of times, but that’s already a saving of 2xCR2032 batteries!
Notice that the new one has a red o-ring seal as opposed to the original black ones. Wonder if it’s a slightly larger x-section?
John
Hi Ray – your reviews are OUTSTANDING – thank you!
I’ve recently started having issues with my Stages & Edge 500 losing synch/pairing. I am setup with the ANT ID stored in the Garmin. Whene power numbers disappear, I’ve had to. Stop, remove the battery, replace and let it re-connect. It is a new battery an latest Stages firmware… Any suggestions?
As an aside – I find your comparisons with the CompuTrainer super useful. I use power to target race and training pace and I train indoors on CT. Consistency and repeatability between these devices is MUCH more useful to me than what the actual numbers are. Ultimately, I’m training and riding my numbers, not comparing my numbers to other people’s.
Thanks for the hard work and insights!
Rich
Hmm, that’s a tough one – and very odd. It almost sounds like the battery might not be snug inside the compartment and then perhaps a bump dislodges it. Any chance you can fold up a tiny itty bitty bit of paper between the battery and the door and see if it holds it tighter?
Got ya covered. Start the warranty process. It’s loose Inside the unit.
Check the internal tabs and see if they are all still intac.
My stages is coming up to 12 months now (brought 04/13). New I had lost one tab about 6 months ago. But over the last 2 months battery life has got worse and it was dropping out at when coming to a complete stop.
So after a pull apart. The internal tabs,not cover has crack and broken off over time. Current fix – 3mm padding with a zip tie. Works fine and the battery life has gone back up too. The drop out started after a real sweaty roller ride.
Anyway – I brought mine from the america when I was on holiday so I have emailed stages to see if I can fix the warranty locally. (Australia) as I have a 4 day stage race to train for.
Matthew
Warranty process worked very smoothly – sorry for the late reply, thought I had responded earlier. New unit works and Stages was very supportive (once I was able to get in touch with them).
I too have just begun to have a battery issue. Only lasts for a few rides indoors. New firmware made no difference. Then upon close inspection, noticed the battery door was loose. I have already had my cover replaced because of broken tabs, but now the issue is with the internal tabs in the unit itself. two or three are broken into small pieces. I am assuming that the “bad batch” of plastic used for the cover was also used in the unit itself. Just submitted a ticket at stages and hopefully they will take care of me despite my warranty was up a few months ago.
First off, great review (update) DCrainmaker and thanks for taking the time to do it. I have ordered a stages PM but haven’t received it yet, I see firmware updates for the unit are possible, but done with iPhones and iPads. The problem I have is, I have all Android devices now minus an old iPhone 3Gs that sits in a drawer but does work still. My question is, are there any other ways to update the firmware since I don’t own a newer iPhone or iPad. I have a Galaxy S3 phone and a Galaxy Note 10.1 tablet. Am I just out of luck to update in the future? Hopefully the Stages PM will come with the latest firmware to begin with, but future updates may be a problem to get. Not sure if anyone else has asked about this issue.
Thanks for any replies concerning this issue from anyone on the board.
★Please refrain from starting an apple/android war
Derrick B.
Yup, as Mike noted, unfortunately at the moment it’s only iOS. Now, Wahoo is very near finalizing their Android app release. And while that’s not Stages, it’s the same company that Stages uses for much of their iOS development, thus, I suspect we’ll see Android based apps eventually hit Stages.
That said, like Mike noted as well – it’s really just a case of finding a friend somewhere to update. The updates from Stages are very infrequent. I think the last (new) one was many many months ago. So it’s not a weekly sort of thing. The only process only takes a minute or two.
Firmware 2.0.38 (?) was pretty recent – although my (fourth) replacement crank arrived with the latest firmware on. It’s pretty hard knowing what they’ve changed, as there doesn’t seem to be anything on their website that tells you when they’ve released new stuff.
Yeah, there was one in early January that was the update for high-speed data/some of the other PM metrics, as announced in September. But I think that’s been it since last summer.
I have asked a few times for a simple firmware change-log on their site somewhere. Mostly, so I can simply reference it in the Week in Review post. Even if it’s just one line-item with a date, firmware version, and then “Performance improvements”.
A log w/ release numbers and dates would be FANTASTIC. See what changes were made, where I’m at along the releases, and decide how much I need/want to bug some iOS user to help with the update. :)
Such a log actually exists:
link to stagescycling.freshdesk.com
They released a new firmware just a few days ago.
It even appears that the latest Wahoo Utility app for Android lets you update the firmware of the Stages. I installed it on my phone (Galaxy S3), and it connects to the Stages, reads my firmware (2.0.38), and offers me to update. I didn’t dare trying, but reading that Ray says Stages and Wahoo work together (or use the same app development company), I guess it’s legit. A bit strange that they don’t mention this possibility on their own website, though. I guess a lot of people are really waiting for a firmware update path for Android.
Thanks for the link!
I decided to give it a try and downloaded the Wahoo Utility App.
A few moments later, it detected the Stages correctly (and warned about the low battery – 21% ) and proposed to update the firmware from 2.0.38 to 2.0.48.
The update process completed smoothly and now my device is up-to-date.
Great to know I no longer need my neighbor’s IPhone! Thanks again.
I downloaded the wahoo utility app and it recognized my stages and indicated a firmware update from xxxx.38 to xxxx.48 was available. However, it fails to update when I attempt to update with my GS3. Back to the drawing boards I guess.
Apparently for the update to be applied, the battery percentage must be higher than 20%.
It may also be the meter going in standby mode after a few minutes. I turned the crank a few times to keep it alive – but did not touch anything as soon the upgrade process had started.
No problems here…
The same happened with my GS3, so they might have to work some more on that. However, since it can connect to the Stages, it should be able to update.
I was lucky enough to borrow an iPhone, and used that to update mine.
Chances are you will have there will be a member of “friends and family” who will have an Iphone. The update takes 3 minutes and the app download is free from the app store. Might cost you a drink or coffee while you’re waiting. I installed my stages 2 weeks ago and even though it is brand new the app did an update immediately. Good news it takes minutes and worked first time
Hi Ray,
Just wondering if you had any insight into use of the stages PM with the Fenix / Fenix 2 with regard to the wrist mounted drop outs.
I have a new Stages PM and it pairs and calibrates just dandy with my FR 310XT but it drops in and out frequently if worn on the wrist (not at all if mounted on the handle bar / stem).
Should I expect better same or worse results from a wrist mounted Fenix 2 ?
Appreciate your thoughts.
Wiz
Unfortunately I have temporarily removed the Stages on my bike so I can test the ROTOR Power Meter (the two are not compatible, due to being in the same place).
Fwiw, I haven’t seen any issues with wrist-based dropouts though in rides thus far, and I’ve been testing it against both a pair of Vector pedals as well as a PowerTap.
Hi
Thanks for the hugely in depth review. I have to confess I have not read all the comments so I hope that I am not repeating anyone here.
I suppose that this is more of a powerTap question than a Stages question but still relevant I think. I currently have a powerTap and plan to change to a Stages when I get a new bike.
Did you do any testing that uncovered greater differences between Stages (and Quarq / Vector) and the powerTap when the chain was badly maintained or filled with mud? I have heard mention before that a powerTap measures after the chain so it will be a slightly lower reading after losses from no oil or rust ect.
As I am moving from one to the other I am wondering if the readings might go up because of this. I suspect that the loss is so small that it cannot be measured.
Thanks
Great reviews, so detailed and informative. Ray your site is my go to for any reviews of equipment. You seem very transparent and unbiased too which really benefits us the consumer but also if a company actually cares about the consumer they only have to read your review and go to work on the improvements.
Keep up the great work mate.
Isaac Far North Queensland, Australia.
I wonder if the satisfaction of Stages customer support is still valid?
I have a Stages on my bike, and have had some troubles where it stopped working, no data, no connection.
So I have a defective product, and have written to Stages, but after 4 days, I have not even seen a confirmation that they have received my e-mail.
I don’t find this satisfactory, and it is far from the stories I have read here, where people get replacements sent the next day.
So maybe Stages wellearned succes is killing their customer support? (I hope not)
Any comments?
Michael
You wrote to the US/general address, or to your local distributor?
I wrote to the EU distributor (info@stagescycling.eu) last week, and got an e-mail back 2 hours later. I have now received a new battery cover, and hopes that this helps solving my problem.
So it seems like that luckily, the EU distributor have another approach to customer service than Stages USA, it has been 15 days since I wrote to them first time (3 followups), and I still have not heard anything back, that really pisses me off :-(
Thanks for your comments. I’ve upgraded from a Powertap G3 to Stages and I couldn’t be more pleased. But I don’t think I can sell the Pwertap for even half of what I paid originally.
The Blimp from Perth, Western Australia
Well, my recently acquired stages worked very well for 3 weeks then started eating coin-cell batteries at an alarming rate. 3 Batteries dead when preparing for a ride, 3 days in a row…. I have been careful at protecting the electronics from water by using duct tape across the unit covering all the electronics pod with a tight seal all way round. This is on top of a correctly fitted cover with red o-ring. In any case not been out in a lot of really bad weather, so 99.9% sure that its not water related. Have of course also updated the firmware.
Went back to the retailer, who explained that they could not replace the unit as the specific model I had just bought was out of stock, but that they would inform the UK importer and advice me when they have stock so the unit could be replaced.
Since then I am now removing the battery after each ride, then refitting and re-taping with duct tape immediately before the next ride. Counting my riding hours and curious as to how many ours I will get on a coin-cell while I’m waiting for a replacement.
For good measure I emailed Stages to inform them of the problem and ask if they had any other advice and like Michael have not had any reply. So perhaps the recent success have taken over form serving the customer, or perhaps they are busy painting crank arms “Sky Blue”.
Positives: Its a very neat solution and so easy to install and manage offered at the right price-point.
Concerns: The Battery pod cover does look a little flimsy (but is easy to operate) Risk of water ingress has been raised by a lot of people but its so easy to upgrade with a strip of duct tape.
Alarming Pattern: Battery drain is a failure mode that seem to occur for lots of users at a high repetitive rate. Really would be nice if Stages could acknowledge this and focus on getting their payning customers sorted on this issue.
My action plan:
1) Keep using while removing the battery between rides
2) Expect prompt replacement with a unit that works (Or a firmware upgrade that stops the drain)
3) Get my money back using UK “Trade descriptions act” (Battery usage 160+ hours specified, vs actual less than 4 hours.
The life of an early adopter…. :) – SRAM Hydraulic Brakes, Garmin 810, Stages Powermeter
Mike, that’s really worrying that this issue is reoccuring on a unit that Stages swear blind has solved every issue. My Ultegra 6800 is fine after about a month – but then so was the last one! I also have a Dura Ace 9000 on my summer bike that I’ve not used for a few months, but the battery is completely flat, so I’ll be interested to see how that goes with a new battery in…
Wrote to: techsupport@stagescycling.com
Rainmaker: I wrote to techsupport@stagescycling.com, I have bought my Stages from the EU office because I live in Denmark
Thanks for all your in depth reviews, I for one really appreciate the effort you go to and the information that comes from that effort. I am better informed.
So…I am on my second Stages. I have tried to make it work with my 910xt and a friend’s 500. The first one that I sent back would work mostly with my 910 if the 910 was close to the Stages. When I was in my aerobars, it didn;t work. So they sent me a code to send it back. No email communication, the box just showed up. So I got the new one and have been futzing with it for weeks. It refused to pair for longer than a few seconds with 910 and same thing with a 500 that I borrowed from a friend. I asked if they wanted to try a third unit or send my refund. We’ll see…
Summer bike came out on Monday after a few months’ hibernation. Replaced battery and seal/door, updated firmware, rode bike. Went to bed. 24hrs later – flat battery.
So this is now the 5th crank I’ve had with this issue – and Stages don’t seem to be any nearer identifying the problem.
Saddleback have insisted I go via the retailer, so I have emailed them making it clear I’m not going to return it so someone can “inspect it” – i expect a new crank (which to be fair Evan from Stages says they’ll send). Merlin made me return a Di2 battery holder for “testing” which promptly disappeared for two months, with the only updates provided when I chased them. If I hadn’t had a spare I’d have had no bike during that time.
Mike – i’ve mentioned you to them as an example of a new model, new seal customer who’s almost certainly never had water ingress – any joy from them with yours?
I’ve got the battery drain problem as well – now on unit no. 5 (XTR Based). It does seem to be triggered by damp weather in my case – not always direct rain. The shed where my bikes are kept does get a bit damp and (mostly) the battery case is dry.
The local Australian distributor has said that there was a bad batch of the ‘new’ cover design which are being replaced.
Sigh. Such a great little unit but I’ve probably spent almost the price difference between stages and Quarq on CR2032 batteries now!
Still not convinced that its purely moisture though…
Aaaaaargh!! New in every way Ultegra 6800 (my 4th) was fine for a month, I guess 50 hours of riding. It’s not been used for a week or so as I’ve been using my summer bike. Got it out today – flat battery. I’ve fitted a new one, fires up straight away – but all the signs are there that the same fault has manifested after about a month – the same as with the other units.
If I’m doing something to make this happen, you’d have thought Stages would have worked out what it is by now, wouldn’t you? This is soooo frustrating!!!
Andy, you must agree that there is something not right here. There must be thousands of Stages power meters out there, so if it was a simple generic problem, we would see more complaints here. Yet you have had 5 crank arms fail. Logic would dictate, that it is something in your environment causing the problem. I’m thinking 2-way Bluetooth communication or something triggering the accelerometer. You could try to move the power meter to another location.
It would of course still be a fault in the power meter, but it would explain the few observations.
I’d have agreed, Uffe, if Stages had managed to identify what’s causing the problem (they’ve had the faulty units to look at!) or if they’d come back and said “we can’t replicate it”.
On one of the cranks it was very obviously water ingress – there was rust in the battery compartment. That’s nothing to do with its environment – they’re supposed to work in the rain.
The other thing is these cranks are on bikes that are used “normally” – i ride pretty much every day, in normal UK weather. I don’t do anything “unusual”. They’re stored in a shed away from the house (although the issue has occurred when i brought my bike into the house to see if i had a “magic shed”. Generally they’ve worked fine for about a month, then they fail. Whilst i accept there are thousands of working cranks out there, there is something that fails in normal use – if I knew what it was and it didn’t involve emigration (interesting that nearly all the examples of this failure – and i’m not the only one – but thanks to great service from Stages i’ve had several replacements – have been in the UK) then i’ll do it.
But all i do with them is put them on my bike(s) and pedal!
A guy on Tri Talk noticed that when he replaced the battery his Garmin could “see” the unit without turning the crank. He’s replaced the battery and his seems to have regained its ability to switch off.
I’ve just been and checked BT and ANT+ on the Ultegra crank that had a new battery about 4hrs ago – it’s still transmitting both BT and ANT+, despite the crank not being moved – so the issue is that it’s forgotten how to turn off. maybe it’s caused by a new battery – as on all occasions my units have worked ok for about a month (about 45-50 hrs of use) then once the first new battery is put in they seem to lose the ability to shut down.
Wonder if we’ve stumbled on something?
That is an interesting idea. And also encouraging, as it might be fixable via firmware.
My replacement crank is doing fine, but I haven’t had to replace the battery yet!
Have you tried taking your battery put after each ride? My second unit won’t connect to my 910 or my borrowed 500. They are telling me to check the firmware on the 500. So…a couple more weeks of no functioning power meter. I’m at the point where I want a refund and get some Garmin pedals. Has anyone successfully gotten a refund?
Hi, i’m looking into stages as my first use with power.
My race bike with shimano dura ace 7900 and training bike 105 5700.
Is it possible to use a dura ace 9000 or 7900 unit on 105 5700
Many thanks Steve
Powertap v Stages Power Meter – wattage comparison video;
link to youtu.be
Stages Power Meter crank and Powertap PRO+ wheel fitted to same road bike on the same ride.
Video is of the recorded telemetry overlaid on the GOPRO video of the ride.
Very cool stuff.
What’d you use to capture the data (two Garmin’s?).
What are you using to capture cadence on the bottom metrics? At several points it seems to zoom way up where the Stages cadence stays fairly steady?
Cool comparison. I really enjoy my Stages PM and have had no problems with it.
If mine were that close I’d be jumping for joy. I’ve run a few test against my powertap and it’s consistently off by 20-30 watts. Doing more tomorrow but their credibility with me is pretty shot so far. Doing a road test is great for summary data but testing it on the trainer pretty much convinced me its not even close.
link to strava.com .
it’s just the cadence transmitted by the powertap hub, which afaik is known to fluctuate at times.
Sorry, so the cadence sensor drops the wattage by 20-40 watts on a Stage vs. Powertap G3? I’m actually getting a ton of smoke blown from stages on this and it’s clearly off. They are supposedly testing it in house; however, I’ve been told the guys at Shimano here in Cali tested these meters and are seeing the same results – off by 20 or so watts. Mine has been off by 26-27 watts consistently regardless of output. Maybe a bad run but kills their credibility with me.
Remember, it’s left-leg only. Thus, your left leg is quite likely lower powered. That’s a fundamental way that the Stages work, and doesn’t have really much to do with the unit.
26-27w sounds incredibly precise however, as I’ve never seen consistency between any two power meters that varied by a set amount of wattage at any level. Mostly, because I’ve never seen data comparisons between PM’s that were exactly the same at any power level (they usually are percentage based).
I only use watts because its pretty much consistently off by 20-30. Percentage would be I’m sitting on the trainer testing, pacing around 110-120w and the Stages is off by 25%. At 150-160w if reporting approx. 18% lower, etc. You honestly think that is incredibly precise?
Update that Stages took it back, tested against a SRM and Quarq with the meter being perfectly accurate. I’m seriously struggling with this.
Here is the thing. If its left leg only that’s fine. If my leg was say weaker by 10% wouldn’t the the variation be progressive, say 100 watts, off by 5, 200 watts off by 10 but it’s consistently off by 20-30 watts regardless of output. I guess the question then is which one is accurate and I lean toward PT.
Had a buddy local riding PT G3 wheelset and bought a stages meter recently. We just tested swapping wheelsets etc tonight with the same results off by 20-30 watts.
Doh, meant to circle back here.
It really is left-leg doubled. Stages clearly states that on their site (as does the review).
The reason you’re likely seeing variance is that people have different balances at different levels. For example, at super-low intensities (soft-pedaling) I’m balanced quite differently than mid-range (very balanced) and again differently a different direction above FTP. If you check out others that have done some poking, you’ll find totally different results based on the individual. Tom A. on Slowtwitch posted a graph of his, which was almost inverted from mine. Making it even more complex, we tend to differ on different days in different ways – such as longer in a ride versus being more fresh.
Essentially, we all differ. And that difference is the fundamental key to understanding whether or not the Stages is the right fit for you.
I’m not the only one seeing this issue. Going to throw our G3s up against a SRM and Quarq so should know which one is off here soon enough. link to forums.roadbikereview.com
I’m still not sure exactly what the issue is but the constant deflection from Stages is its an imbalance. Same exact imbalance me and two other guys with these meters are seeing local. I finally got extremely fed up dealing with them and scored a brand new 9000 SRM. Quick test today absolutely confirms what I knew day one. It’s actually worse against the SRM being off around 40 watts, guess that’s pretty precises being off 20% at 200 watts? So that’s two sets of powertap wheels and an SRM with two different riders getting the same results. Odd.
As I’ve told them I honestly could care less about the technology, bores me to death. It either works or it doesn’t. Personally I’d cut back on Starbucks for a month and pick up a Riken instead.
Cheers fella, Yeah – 2 garmin 705’s with the same firmware (3.1) and same settings, I wanted to reduce as many variables as possible and have always found the 705’s with that firmware to be rock solid (at least for me)
I am really interested in this power meter, since it is one of the least expensive and easiest to install.
But I was wondering if there is anyone out there that does not have any issues with this power meter? I understand most people here post about the problems they have with this Stages, but I also would like to know if anyone is completely happy with this power meter?
Kojtl1000
I bought one 9/13 and had it replaced a few months later do to faulty seal and it got wet. The new one I received 1/14 has had no problems other then the battery cap busted a prong. They immediately sent me 2 new caps. I have been very happy with this one. No battery drain. CS has been on top of every email I sent from the start. I highly recommend getting one.
Owned one since beginning of the year with 2000 km on the same battery. To be fair it sitting on my nice bike, and did not ride in any serious wet weather yet.
A comparison on the Tabayesco climb, Lanzarote (10,3 km 5,7%) rendered 264 W avg. on Stages and 271 W using bikecalculator.com. Comparison on the trainer with the Power2max I have on my other bike is also favorable.
In other words I’m very happy about the Stages power meter, but if course concerned about the reliability issues described here, and I think Stages should get to the bottom of this, and be more open about it.
Great product. But the reliability Ian an issue. Knowing 6+ people that have gone through more than 2 units each is a concern.
Wet raining is an issue. I had mine replaced due to the internal tabs breaking. I put a fresh battery in and taped the crank in electrical tape. Even though it’s a new unit and meant to have the new seals
A friend picked his up 2 weeks ago – did a wet ride and now have drop out issues. Told him to leave the battery out. He’s now getting a refund since the downtime is major in Australia.
I have given my new stages back to my lbs to look at. Out of the box it paired perfectly with my garmin 510 and has produced very conisistant readings. Unfortunately they are consistently 50% higher than my powertap. I have previously compared my powertap on vbarious mountain climbs with power calculators and normally the powertap was slightly higher than calculated (within 2 – 3 %).
The stages gives results such as 3 – 4 hours at 290 watts average and average heart rate of 110 or less. My estimated 1 hour threshold at about 520 watts very unlikely.
I had trouble pairing it with my suunto ambit 2 and virtually had to insert the watch inside the power meter After pairing i could not get it to detect the stages whilst riding. I am wondering if the transmitter is a little weak as i expect the suunto aerial is also potentially weak judging by how close you need to be for it to pair with any ant+ transmitter.
Ray, I wonder if you can share the files where you ran a stages on a computrainer, I’m interested in calibrating the stages vs a computrainer as I test and train on a roadbike on a computrainer and have the stages on my mountain bike which I race. I realize they will be different and have no issue with that but I’m trying to determine how different they might be so I know what to set the FTP on one to be as close as possible to the other.
Unfortunately my mountain bike has a 142×12 rear axle and can’t be placed on a computrainer to do this sort of test myself!
thank you!
I’m having problems with battery drain and I’m unable to connect with Stages App to update firmware. My Iphone is unable to find the power meter even with new battery installed. I have been in contact with Stages and they gave me some ideas to get the bluetooth issue to work. But nothings works and I’m a bit frustrated. Stages EU will send me a new battery cover and o-ring. But I guess that will not help unless the new cover makes the battery fit better or something if now that’s a reason for battery drain.
Is there anyone else having BIG problems connect your Iphone with the power meter? I have tried both with my Iphone 5s and Ipad Air with no luck.
Erik. Hold power button & standby button on your iPhone until apple logo appears. This will clean up any ram being used & refreshes iPhone. Then try again.
Erik: Just an oddball suggestion. Since you said you had paired the Stages with multiple BT devices (your 5s, your Air), is it possible that you are paired with another device — and that’s why the Stages app can’t see the power meter to update its firmware?
To test this, banish everything but your bike and your iPhone from where you are. Maybe even go a block or two down the street! Put on a tinfoil hat! Whatever… Now try it. Any change?
And the battery door is a bit problematic. If the door isn’t inserted all the way, you might have a bad power connection. Just for a test, try taking the o-ring out, but a fresh battery in, do a happy dance. The door is much easier to insert now. Any change? If so, now figure out how to get the o-ring back into the solution…
Not associated with Stages, just a happy owner. Yes, I’ve had both these issues (“D’oh, my darned iPad is talking to it. WTF!”). You may well have another issue, but perhaps you’re like me and find it’s something simple and stupid in the way.
Try “BLE Utility” apps with your iPhone (free), this is my favorite app to debug bluetooth issue.
And remember, bluetooth smart can only pair with one device, one apps at same time
To clean pairing, close app or kill app (2 home + swipe up) or turn off blutooth in setting…
Good luck !
Note: happy stages power user, without problem…
Just wanted to thank you for the “happy stages user” comment because with all the negative input I have not dared buying one.
I’m very tempted to get one for my mountainbike. There I don’t see left-right power as an issue and would still like to get an idea of the power output without weight punishment and not having to move away from my pretty and well function XTR crank set.
Would be great to hear from happy mtb Stages users!
I have now tried to shut down every other device with bluetooth, closed all apps on Iphone and did another try with/without o-ring and battery cover on. It’s impossible to find the power meter with bluetooth. If I turn my Edge 800 on, it’s connected directly with ANT+..
Since there is a battery drain issue which could be a result of water leak, there is no sign of this inside the power meter but I have one ride in heavy rain in the last couple of weeks. Battery drain issue started this week..
Is it possible that the bluetooth signal can have been effected by water/moisture but not ANT+? I will wait for the new battery cover and see if that can solve some issues otherwise I have big hope on Stages god reputation about replacing “broken” devices.
Despite this I have been super satisfied with Stages power meter, and my faith in Stages is not hurt yet..
Hi Ray.
Do you mentioned some connectivity problems between the Stages Powermeter and the Garmin 910xt? My Stages arrived on saturday. It works really fine with the iPhone4s (Bluetooth and Wahoo ANT+ Dongle), but with my Garmin devices (Edge 800 / Forerunner 910xt) i have huge data dropouts. And both Garmin devices do not recognize the Stages PM as a cadence sensor.
A look into the internet showed me, that this is a common problem and is a issue of Garmin… Take a look here:
link to forum.slowtwitch.com
Did you hear anything from the Garmin gys, or do you know anything about this problem?
regards,
Florian
Yes, it’s a 910XT thing and affects more than just Stages if in aero position. I asked them in the past and they said they were working on something there, but it sounded like more guidance than anything. I’ve got it on my to-do list for an e-mail this week to see what’s up/new.
As for Garmin devices recognizing the Stages as a cadence sensor, that doesn’t happen. The cadence comes automatically when you pair the Stages as a power meter – it’s part of the power meter profile to take it from devices that support it (as Stages does).
thanks for the fast response. It would be great if you can keep me up to date. Cause i have to decide if i keep the Stages Powermeter or send it back. At the moment the Stages PM is pretty much useless for me… :(
Hi Ray,
I managed to get a cheap second hand stages off ebay and I was wondering if its normal for it to show far less power on the turbo than on the road? On the turbo I struggle to put out more than 2W/KG, but my FTP is about 4W/KG, any idea why?
Cheers
That’s a bit more than normal.
Some people struggle to put out power on trainers (compared to outdoors), and for others it’s the inverse. For me, it’s the inverse. I can pump out trainer power all day long, but on a flat course it’s far more difficult for me. But not quite the separation that you’re looking at there.
Cheers, I am really confused as to why the difference is that much – admittedly I do hate trainers so I use it as little as possible and its now been packed away until next Winter anyway!
Guys….the Garmin 510 update from 2.8 to 2.9 included this comment:
Fixed an issue causing ANT+ sensors to become disabled when searching for a new sensor.
I was having issues with my garmin losing connectivity to the Stages like people are commenting on here. As soon as it the garmin was updated the issue went away.
The other thing I recommend is programming in your Stages Ant ID instead of letting the garmin find it. If your Ant id is 6088 then input zeros in front of it in the Ant id screen on the Garmin…i.e. 0000006088 and it will pull it it up right away.
The issue is with the Garmin not the Stages.
I borrowed a friend’s 500 and did an update and that didn’t seem to help. I cannot figure out how to manually enter ANT ID. and I couldn’t find it in the manual. Can you give instructions? Thx.
Sure. My issue was with a Garmin 510 not the 500 but the instructions below are for the 500 since that was your question. I am not sure however if your 500 literally can’t find any power unit it may not pop up the “Sensor Details” option in the Ant+ Power menu. Hope the below helps.
Hold down Page/Menu->Bike Settings->Select Bike (i.e. Bike 1, etc.)->Ant+ Power->Sensor Details->Highlight the Sensor ID & hit Page/Menu->input the Ant+ID with zeros in front of it if needed.
Hi,
I’ve heard good things about Stages and now see that Sky is using Stages, but my experience has been anything but positive. The first Stages powermeters that I used were earlier versions and had issues with connectivity and the battery seal. I know that Stages has made some improvements to firmware and the battery seal and so should have addressed a bunch of their first run production issues. But still, my first experience wasn’t great.
A few weeks ago I got a new bike with the Stages powermeter on a Shimano Dura‑Ace 9000 crank. The power seemed off (low) and I thought maybe it was the fit on the bike. So, I had the fit looked at and adjusted a bit, but that didn’t seem to improve the situation. So, I decided to test the Stages against a Powertap and found that the Stages power was 19% lower. That’s an unacceptable variance. Actually, I’d say anything nearing 5% variance is unacceptable. So, 19% is off the charts.
Have you heard of anyone else having this issue? Thanks!
Have you looked into testing your balance with a power meter that supports that (i.e. Vector, ROTOR)? Ultimately, the Stages simply doubles the left leg. As a result, imbalances will result in what you see.
Hi,
Thanks for the reply. I’ve been using a Quarq that has a calculation of the balance. I have worked on equaling out my balance and am usually 50/50 or 51/49. So, if anything, my power should be a tick up with the use of Stages.
I’ve talked to Stages and sent in my comparison files. They can see there is an issue and so we are going to send the powermeter back in for testing on their end to see what they can find.
When you did your comparisons, were the watts produced on Stages comparable to Powertap, SRM and or Quarq?
Thanks!
They were similar in most cases, however once I cleared my FTP level then things separated quite a bit (read: my balance became inbalanced). Check out my Vector review where this is shown really clearly.
Kevin,
I just purchased a Stages PM and seem to be having the same issues with the power being meaninfully lower compared to my tests on the computrainer. I’m running 30-35w low on the Stages at most levels above 300w and more pronounced up to 50w at levels around 150w. I seem to be more in the 10% variance range, which seems unacceptable. My HR had been telling me that the wattage seems low but finally tested it on the Computrainer (2 different ones) and seems to be consistently off. Did you get any result from Stages? I’m going to send them a note later today.
Jon, I sent the comparison files I made on the Stages and Powertap in to Stages and they agreed that there was an issue, so we set up for me to send my Stages PM back to them. I just recently did that and it arrived to them yesterday. Their initial comment was that 2 tabs on the battery door were broken which could be causing powers and therefore a lower avg. power reading. I guess that makes sense being that there have been so many issues with the battery door on the Stages PM’s, but I hope to know more today after they run some other tests.
Thanks for the quick reply. Let me know if you hear anything insightful from them on the issue. I’ve only got 5 rides under my belt with the PM and only one was outdoors but overall wattage felt low. I’ll email Stages and see what they tell me as well.
Stages did some work on my power meter and returned it to me this week. I got it on the bike and went out for a ride this morning. The power seemed to be where it should be. However, I’m not 100% sure that it’s correct because I didn’t run tests against any of my other power meters. But, based on the efforts I was doing and my corresponding heart rate, I’d say it was correct. I’m going to do a few more rides and if the numbers continue to make sense, I’ll have to say that Stages has corrected the issue with my power meter. If the numbers don’t look right, I’ll pull the crank arm again and run tests on my other bike against another power meter.
Kevin – thanks for the update and glad to hear the new one is more in line. I’ve been sending emails back and forth with Stages on the issue and sent them a comparison file of my Garmin vs. a Computrainer where I did 6 intervals of 5min at VO2 max levels. Looking at the data and averaging it out for the 6 intervals, I was 35 watts lower on Stages compared to the Computrainer. We’ll see what they say but at this point i’m resigned to lowering my FTP accordingly and using the PM as my main source (despite what that does to my ego). Appreciate the follow-up.
For those having issues with the 910xt, I have this unit and have not had any connection problems. I did skip the calibration this morning by accident and no power would register. I turned the watch off and then back again, calibrated per the prompt when you turn the crank, and it was good to go. Not sure if this helps but still learning the ins and outs of technology.
I got a new arm after my first one was having water ingress issues. The new one seems to be reading 20-30% lower than the old one. Unfortunately i don’t have another power meter or computrainer to compare against. So I verified this using a number of different methods (perhaps none 100% convincing in themselves, but together i think it’s pretty clear). Interesting to hear that others have had the same problem. My shop have been great and are getting me another arm to try.
excellent work! Thank you!
For the group:
I recently purchased a Stages PM for my road bike. I have been using it for a little over a month and have been very happy with the results. I spend time between two locations, and I now that I am cycling frequently enough (3 – 4x per week) that it makes sense for me to keep a road bike in both locations. I have been looking seriously at a couple of bikes that use FSA hollow carbon crank arms. My understanding is that Stages cannot work with a carbon crank arm because of the flex characteristics.
Stages recommends purchasing their alloy FSA crank arm and just using it with the carbon on the crank side. Does this make sense? Or is it better to consider swapping our for an all alloy crank? I definitely want a PM on both bikes and the Stages price point is appealing.
Any thoughts most appreciated.
Hi Ray,
Love your work and always point anyone with bike tech questions in your direction. Recently bought a stages and have been having problems with my edge 500 and power dropouts. I emailed stages about it and they said that it could have something to do with the edge 500 loosing hrm signal and as a result it drops the pm signal in favour of trying to pick up the hrm again. I was wondering if you’ve experienced this and have any soloutions in terms of making the edge 500 prioritise the power meter and not the hrm? There are no problems when I’m on the aerobars but when I sit up the power signal drops immediately….
Hmm, I’m not too certain I buy that specific explanation. The ANT+ chip is multichannel and I’ve never heard of it dropping one channel for another, and certainly never prioritizing.
Now, I can buy there being a signal issue – though that’d be the first I’ve heard of on the Edge 500 (FR910XT is very common).
One thing to try is temporarily take your Edge 500/rubber band mount and stick it on your top tube of your bike (basically, close to the Stages PM). About half-way between the seat and the stem. See what happens. Helps to narrow things down.
I read somewhere that Stages might be working on a dual power meter where they will measure power from both legs. Does anyone know more about this?
Well looks like it’s started again. Had the new crank 3-4 months. Changed the battery before a 3 day – 4 stage race On Thursday. Popped up in the Garmin this morning the battery was near flat.
I even run elec tape over it. But I say it has got damp from the lovely race on Fridays road race stage. I’ll touch base with stages USA today and see what they say.
Matthew
Does your current power meter have a red o-ring? The red O-ring plus the new battery door are supposed to prevent the battery draining issue due to dampness. I received a replacement back in January that supposedly had a redesigned battery door but i found out recently that one drained the battery after riding in the rain or after washing my bike. I received a replacement with the red O-ring. Hopefully the battery draining problem is fixed once and for all with this power meter.
Yep red ring. The water is via the back not the battery cover I would say.
Matthew
I’m still wondering whether this is an initialization issue. It seems that the problems always start after a battery change. It’s a common problem with ultra-low-power electronics, that they do not reset properly when the battery is changed. I would try to short-circuit the battery terminals for a couple of days before mounting the new battery.
Ran my Stages for 6 hours in the rain two weeks ago, and still on the first battery after 3500 km.
Update: The replacement power meter with the red O-ring survived the first bike wash. So i am hopeful that my battery-draining issue has been resolved.
It’s not an initialization issue. The battery in my old leaky Stages power meter would work fine until i wash my bike. When i didn’t wash my bike for several months, the battery lasted just as long.
I think you need a new shoes!
Great, you buying?
Great review… Keep up the great work.
-Not for bragging rights but to validate my statement below.. bike time was 4:50 (112 miles). Body weight was 129 lbs and avg watts per kilo was 3.8. Stages (in my opinion) was the best option for the cost in weight, flexibility in wheel options, and overall dollar cost.
For anyone reading this and considering the options for a power meter… here is my experience. After hearing about stages from my bike shop (the owner a former CAT 1) and researching your review, I purchased the stages dura-ace 9000. Although I had to wait a few weeks for it to arrive, (this was nerve wracking with my A-race approaching rapidly) it was a very good investment. It arrived in time and I had a few weeks of training left to test it and recalibrate my strategy. If I understand weight to power issues correctly… this was the best option. For the cost in weight (ie how much more does it add in weight) it added a mere 20 oz vs. almost a pound of weight for the power tap. Additionally crank mounted power meters provided me a greater flexibility for rim options without purchasing multiple power meters. I.E. I used heavier and less flat prone clenchers for training saving the expensive tubeless tires ($120 ea) and rims for race day and allowing training to be harder as well. Another important consideration was cost. Stages was significantly less than other crank mounted systems. Therefore… and with your comments from your review, stages made since.
Stages was consistent over time and I knew what I was going to push on race day based on training… It was irrelevant (for me) if there was any difference between systems. I didn’t understand how improved accuracy (1 crank arm vs 2 etc… ) would help me speed up and yet conserve for the marathon. If anyone understands this then please let me know. I am assuming that even a 5% fluctuating variability (6 watts) is better than the calibration in electro-biological muti-stage systems (our legs). I had improved my performance significantly from the previous year, was second off the bike in my age group, and 58th out of 2500 overall counting pro’s. Power meters made a significant difference in my ability to conserve for the next leg of the race. I hesitated to go with the stages due to the newness of the technology and the likelyhood for bugs. It takes time to work them out. It always does. But the technology used in stages isn’t rocket science… (or is it?) so it shouldn’t take too much back and forth to get it close enough. It was a bet I was willing to take. Stages worked… I shaved nearly 2 lbs off the total bike weight (original zipp old tubulars and powertap were HEAVY! but a better option than guessing). I was able to manage (per strategy) output power over the full distance of the bike leg instead of guessing. That made a difference in my total race time. Total improvement was nearly 35 minutes from the previous A-Race and a 20% overall improvement in rank (I know what some of you are thinking here so I will add “without the use of drugs”).
Training and strategy were more significant than 2 lbs of weight, but having trained very hard and having improved that much, I had a chance at a podium. I wanted the best equipment possible. Stages won in a “due diligence” comparison analysis and during use it worked well.
Hopefully this is helpful for anyone who reads down this far.
Hi Rainmaker! I have really enjoyed your two studies as they are very methodical!
I’m thinking about buying Stages powermeter but I have a Garmin 910XT and have seen that there are many connection problems.
Even this problem persists?
Putting the Garmin handlebar signal is lost more easily?
Thank you very much for all your work!
Xavi
@Xavi:
I had similar problems with my 910xt. In the last weeks i tested a lot and it seems the
problem only occurs, when the watch is on my wrist and moving around (like turning/pronating
the arm, switching hand positions, etc.). When the watch is mounted on the handlebar/extensions
and stays in this position, the connection is good. No more data drops. I think the watch needs
a few moments to receive the signal. And when moving the watch around, the watch looses
the signal with bigger movements.
So i bought the Garmin Quick Release Kit, place the the watch on the handlebar/extension
and everything works fine. When i enter T1 i move the watch from my wrist to the handlebar
(leaving the strap on my wrist during the ride) and after the ride i move the watch back
on my wrist and everything works fine also during competition…
Not the best imaginable solution, but it works.
hope that helps.
Thanks for your help Schmott!
Nave the 910xt and I can’t get it to wok. It asks to calibrate, and then I get no readings. My three emails are going unanswered to Stages. This is my second unit. This one does the same thing with a mounted 500 as well. Mounting my 910 didn’t help..
Ultimately, it’s unlikely Stages is going to be able to solve this. I’m reasonably convinced it’s a Garmin 910XT problem, and they came reasonably close to admitting as such last fall (but never quite crossing the line).
Unfortunately there’s no hard and fast ‘will it work’ answer, since it appears to vary greatly on:
– Exact hand position
– Exact position of watch on wrist
– Which wrist
– Your body type
– Your bike type and what might be impact signal between crank and watch
– Tidal patterns
I kinda feel for Stages here, since they are at the mercy of Garmin on this, and Garmin is kinda trying to pretend that it’s a user issue. And, further, it’s actually not Stages – but rather appears to be many crank area power meters, even including Garmin’s own Vector (and Quarq’s units). It’s simply that there are more people buying Stages with the 910XT than Vector. I suspect that Vector buyers are more likely to have a separate Edge device (and informal data I have based on review comments seems to agree with that).
One would have thought that Stages has solved the battery drain issue by now. Unfortunately not. The battery in my two week old stages crank lasted only for 30 hours. Subsequent batteries lasted only for one ride. Stages will replace my crank (some mention of not going into sleep mode …. though this can’t be the only reason), however, in the roadie forum that I frequent a couple of people report the same issue. If you check other interne forums the same story pops up frequently. In a UK triathlon forum people ride already the third replacement crank. These are very recent reports and can’t be related to poor sealing or the software issue supposedly fixed by the firmware update.
It sort of looks like that they still haven’t figured what the real reason for the issue is. Never purchase a first gen product!
It is straightforward to test if the unit has not gone into sleep mode with the phone app. If it is not sleeping, the app will be able to connect to it, if it is sleeping then it will not. The time from inactivity to sleep should be 5 minutes in the later firmwares, so just let it sit for 5 minutes and then check with the app.
Yes, I know. Therefore, this can’t be the only reason.
Other people got feedback today. Different explanations for the same symptoms.
I’m convinced its a Garmin problem too. Just spoke with them about my issue — works on road but not in house on trainer. They suggested that my home wifi signal maybe scrambling the signal and the Garmin won’t read it. Sounds fishy to me, but I’m going to move to a different location in the house and see if there is any improvement.
An update from me and my battery problem – about six weeks ago both my Stages power meters stopped draining batteries – no idea why, but I assumed it must have been because I had a duff set of batteries – which I found amazing given I’ve used two different sorts, but I couldn’t think of anything else. Both have worked flawlessly ever since.
Over the weekend my Edhe told me the battery in my power meter was low, so I replaced it with another one of my “good” batteries (I also updated the firmware to 2.0.51 – anyone got any idea what that’s supposed to do?). And lo and behold, today my brand new battery is flat. I even used a paperclip to short out the power meter, as some people have recommended. So I think the issue I’ve been having is something to do with battery replacement.
What was interesting tonight is when I put a brand new battery in the meter still didn’t respond – but about five minutes after putting it in all of a sudden it “woke up”.
So either the new firmware has brought the problem back, or there is something that happens when you replace the battery – which inadvertently I got right a few weeks ago and then got wrong yesterday!
If your power meter is still under warranty, i suggest getting a warranty replacement. My current Stages power meter is the fourth one and i think this one is a keeper. It survived a second bike wash without draining its battery. My previous two power meters would complete drain their batteries within a day after a wash.
This is the second repkacement DA crank and I’m on #4 Ultegra – I don’t want to rain on the parade, but every one I’ve had has been fine til I replaced the battery. It’s not a water ingress issue – it’s something that happens when you change the battery.
I’ve just been and checked that the crank with the new battery in has gone to sleep – it has, then it immediately “woke” when I spun the crank – so we’ll see how long the battery lasts…
Answer? It didn’t last. Didn’t ride the bike for three days and when I checked last night the better was flat. Stages are now back to suggesting it’s (a) water ingress or (b) the battery terminals are squashed. They just don’t seem willing to accept the growing evidence that something happens when you replace the battery.
Regarding changing the battery, I have used my Stages for one month now, with no issues, but also no soaking wet rides yet (but I have washed my bike, and a couple semi-wet rides).
I have not changed my battery, but I have removed and replaced the battery twice (to test something), with (apparently) no ill effects. If the theory is that replacing the battery causes issues because the unit is then momentarily completely unpowered, then removing and replacing the battery should be the same as actually changing it.
I’m not dismissing your theory, but I think there has to be something more to it than just changing the battery.
I’ve had my Dura-ace 9000 stages for about 2 months. First 6 weeks was great but also no rain since I used my rain bike those days. Then, I had to replace the battery. After that, I had lots of problems. Also, I cannot tell if the battery cover originally came with one tab broken off or if that happened when I replaced the battery mid-ride one day. Anyway, the bike then got soaked in rain heading to a race. Despite new batteries, did not work. Then, I let it dry out for a few days and, with yet another battery, it started to work. But, that battery only lasted 1 week. Enter another new battery and I had trouble for a while getting it to find the power meter then it finally did and all has been good for a week. I’ve got the stages wrapped in two layers of black electrical tape until Stages sends me new battery covers. So, I don’t know if the issue is that it get wet or there is something else going on that is independent of the dampness issue. Stages has been pretty helpful so far. I’ll see whether the new battery door solves the problem. If not, I’ll ask for a replacement crank. Any thoughts? By the way, I’ve been running a power tap simultaneously (in case the stages dies on me) and, although I’ve not plotted any downloads, it seems to me that the stages runs maybe about 5-15 watts higher consisently, but otherwise they track closely. Any thoughts on that?
link to youtube.com
my stages v powertap comparison was very close – I run them side by side as well. Other people have more disparity. For me it wouldn’t be an issue as long as the stages remained precise (vs accurate), ie. if you put the same effort in it gives the same results. Also on my second satges which seems to behaving itself but we are out of the bleak british winter weather so it’s not really 100% tested.
More battery issues – I just posted the other day and must have jinxed myself because my battery went dead a few hours later after less than 1 week of use. I messed around with the new battery install and it seemed like it took a good 20 minutes before I finally got my garmin to “find” the power meter. So, back in action but this stages is killing batteries in less than 1 week. I’ve heard one comment that without the right battery cover, the battery won’t stay properly seated and maybe that’s why they keep going dead. But, I’m feeling like my patience with this is wearing thin. I’ll try the new battery cover when it arrives and if that doesn’t fix it, will ask for a replacement. Any thoughts on why it would take so long to get the garmin to find the power meter after I insert a new battery? Any tricks to “wake” up the stages so the garmin finds it? Is it better to actually ride it while searching for the power meter?
Hi All
I had to change my battery on my Stages for the second time yesterday. First time worked without a hitch so I was very disappointed when I had power readings dropping out on the way home last night. I stopped once to re-fit the battery but it still kept dropping out.
I was pretty annoyed with this as I have my biggest ride I have ever done (120miles) on Sunday and if I ever want my power meter readings recorded for posterity it’s Sunday!
I phoned up Stages and a very helpful guy said that it might be water getting in (it’s been boiling hot and bone dry here all week) and that when changing the battery the contacts can get mashed down and then don’t press against the battery as much.
I went back out to my bike and sure enough the 3 spikey contacts at the base of the battery compartment (they make contact with the middle of the battery, not the edge) were all completely flat.
I GENTLY pulled these up with my finger nail, and pulled the contact at the edge of the battery out a little and that seems to have done the trick.
I have only done a short test ride but it looks good and makes sense.
I did have a bit of trouble changing the battery this time and probably used more force that I should have done. This is probably what pushed the contacts too far down.
A lot of people on here seem to complain of issues after a battery change. Have you all tried bending the contacts back into place?
Note: You really do need to be very gentle. They are tiny bits of metal and if you break them off that’s probably a £700 paper weight.
I am going through about a battery a fortnight. Only about 5-6 rides. Certainly washing speeds it up.
I have had a battery cap replacement but they didn’t put the red o-ring in.
Things didn’t improve.
I have had two firmware updates since then and I changed the battery and swapped out the o-ring for the red one.
So new battery and o-ring as per yesterday and the latest firmware.
We’ll see how things go.
BTW connections have been easy straight forward for me. Iphone 5 or Fenx2.
BBTW The Fenix 2 doesn’t loose connection with the stages at all while being worn on my left wrist.
Wiz
Have you folks with the battery issues tried removing the battery between rides?
I installed my THIRD Stages two rides ago and it seems to work fine with my borrowed 500. With the 910xt, it had a lot of power drops when I was in the aerobars. Not sure about when I had it closer to the meter because my ANT stick isn;t working right with my computer so I couldn’t read that one. This is two rides. We’ll see how it lasts…..
BAttery will probably give out in a day or so,,,
Thanks for this extensive review. Can you recommend which Stages crank to get if I ride SRAM and have a BB30 bottom bracket? It appears they only offer SRAM Rival which is GXP. Would you advise against getting a GXP adapter for a BB30 frame or will the adapter have no impact on power measurements?
Could you also comment on whether you plan to review the Cateye Strada Smart head unit: link to shopcateye.com.
I’d be very interested in seeing a “budget” approach to power monitoring/recording via Stages + Cateye Strada Smart.
Thanks!
I didn’t have any plans to date, but, I also didn’t know they made a new little BLE-capable one. I’ll figure out how to order one and poke at it a bit.
Thanks, yeah I’m wondering if the new BLE Cateye is good enough to supplant a Garmin, allowing the phone to do all the heavy lifting.
Coincidentally, it looks like SRAM just announced their new Rival 22 groupset today, so you can ignore my first comment/question asking about BB30/GXP adapter…Rival 22 is going to have a BB30 option now, so presumably Stages are going to make a crank arm to go with it.
Anyone get the right/left balance working with an edge 800?
Thanks
Matthew
This is a metric that the Stages can’t deliver, so the answer is a resounding no.
I know this was asked last year but I didn’t see an answer. Does the stages pm read accurately with osymetric rings or does it overstate the power. I noticed some sky riders are using them with the osymetrics.
Also, as I’m about to make a decision on buying either stages or power2max, are the battery issues sorted with the stages yet? How long between changes, seems to be very varied opinion.
Concerning the oval rings only power2max seems to have come clean on this (50 samples a second, weighted by angular velocity). Stages could do the same as they use an accelerometer, but since they don’t say, they are probably not doing it.
Anyone have tips when replacing batteries? I seem to go through one battery per week and will soon ask for a replacement power meter. And, this has continued to happen even with dry weather, although it seems like one torrential rain storm was the start of my problems about one month ago. Anyway, the other day the power meter did not work, and I installed a new battery. After performing the search function many times to no avail, I finally just put my old power tap wheel on the bike. Then, the next day it worked again. Seemingly no rhyme or reason to it at all.
I’ve been watching these comments regularly with great interest. I have had my Stages Ultegra crank since last September, and just am not having the same negative experiences as a lot of others. I live in Florida, and it rains every afternoon (and I seem to get caught on the bike in these 5 minute downpours), which causes no problems with my power meter. With the rain, I am forced to wash my bike pretty regularly, once again with no issues. I have replaced lots of batteries, and I mean lots, and have never had an issue. I do not have any extra protection for the battery, except for the o-ring not he battery door.
With those that are experiencing major battery issues….are you sure the batteries are good? When I started going through a bunch of batteries in January, it wasn’t the power meter killing them, it was the batteries themselves that were bad. I bought a 20 pack of Sony branded batteries from Amazon, and the first 8 died pretty quickly. I opened the remaining ones, and the voltage was less than 3.0 (sometimes as low as 2.3 volts) on each of the remaining ones. As it turns out, these Sony batteries are just old stock (and the Amazon reviews tend to bear this out). There are no date codes on any of the Sony batteries.
I started ordering Energizer batteries from another supplier that I know turns their inventory over very quickly, and have never had an issue since. A quick check in Garmin Connect shows my current battery has over 100 hours on it, and the current battery voltage is right at 2.9. I would be interested to know at what point the voltage threshold drop will no longer turn on the pod’s electronics.
The Energizer batteries have date codes on them, so you can google when they were made.
I did wonder whether it was batteries when both my power meters started working perfectly again, but then my Dura Ace one started battery draining again immediately I changed the battery. These are branded batteries (some Maxcel, some Panasonic, all with long dates and all testing at 3.2V+ when installed and coming out 24hrs later reading 2.3V).
My Dura Ace one has now decided to work again – I put a new battery in, and after 24hrs the iOS app had the battery showing yellow. I put the bike away expecting the battery to be flat the next day – but then it showed as full! I’m sending it back for a replacement anyway, but I do wonder whether batteries are the problem so I’ve just bought a batch of Duracell with long dates on them.
So we shall see…
Hi Andy,
Wondering if you had any update/progress please.
Thanks
I have an Ultegra6800 meter, which I purchased in UK in June. First battery (supplied) lasted about 50-60 hours. The second battery went from full to yellow while the bike was sitting in the basement (vacation). I’m trying with a brand new Duracell now to rule out dodgy battery supply issues. I have the latest firmware. Interested in other’s experiences – as posted below, many happy users don’t report, so possibly it’s a few defective units rather than general problem, so I need to decide whether to push for replacement.
Have you contacted Stages support?
I did contact support, they suggested defective batteries, and to try new ones which is what I am doing now. They have been responsive, but I am concerned this might not be about the batteries. I have three other ANT devices which use the same 2032 battery type (HRM, two speed sensors) – all are still on the same battery after one year, whereas I am on the third battery now for the power meter. I also had problems with data dropouts during a long sportive (200k), which they thought could be data interference, and recommended hard coding the device ID. That was before battery died, so maybe it was related.
Hello everyone, I have develop a ios application to show in realtime your pedalling force (around 40 times per second).
I need some beta tester. You need a Stages Power Meter and a iPhone 5 and up
The application is done to be use with a home trainer, not on the road.
Please contact me at bike.stroke.analysis@gmail.com
Thanks for help !
I’m trying to calibrate my Stages meter with my Edge 500, and while the Edge recognizes it, the Calibration screen simply says, “Calibrating…” with dashes underneath. The meter calibrates fine through the Stages app using Bluetooth.
Suggestions?
Have you updated the Stages to the latest firmware (using the app)?
Yep, did that this afternoon. Garmin firmware is up to date too.
I’ve gone through the calibration process at least a dozen times trying the 12 o’clock position, and 6 o’clock. I even turned off the other sensors in case they were somehow interfering a, but no change. Once this morning I had 882 pop up, but it disappeared and I’ve tried to replicate it, but to no avail. I’m in touch with Stages tech support, I was just hoping that maybe someone else had the same problem.
Well, I just updated my Stages from version 2.0.51 to 2.0.58, and I am now observing the same problem as you. Stages must have broken sometthing with this update, unfortunately.
Hmm, I just tried it again, and this time it worked also from the Edge 500. It would appear that at least it isn’t consistently failing.
I think I’m going to start from scratch with the Garmin, setting up all of the sensors again. I was happy that I got it at least once, as it tells me the devices aren’t broken, just a communication issue.
If you’re using the meter constantly, how often do you find that you need to calibrate it?
Since it takes literally 15 seconds to do it (just answering yes to the popup on the Edge), I do it before every ride. I get pretty much the same number every time (+/- 1), so in reality it is probably just a waste to do it, but I’m an engineer, so…
If I could get mine to the 15sec stage, I probably would too :)
Here’s hoping I have some luck today
Okay, I got it. I didn’t have the HR monitor out there while I was trying to calibrate before, so it was constantly searching for that while trying to deal with the Stages meter. I decided to wear the HR monitor out there this time and sure enough it was calibrated within 30sec. I had some issues with the speed/cadence sensor not picking up, but I just reset it and it is fine now.
One last question because I don’t have it in my data fields; I know the Stages meter has an accelerometer to determine cadence, but does that show up on the Edge, or do I need to put the magnet back on?
Thanks for all of your help!
Jeff, no magnet needed. Once the Stages power meter is paired up with your bike computer, the cadence reading from the power meter will take precedence over any other cadence sensor. I still keep the magnet from the Garmin GSC-10 on the crank arm because just in case the Power meter misbehaves, i can disable it and still get the cadence from GSC-10.
Awesome thanks! I may put mine on as well, just as a backup.
Really excited to start using the power meter.
Hi Ray,
Your reviews are awesome, I learn a lot reading them and with this last one I think I made my mind of which Power Meter I’ll get, but I’ve got one question.
I’ve have one bike with a Dura Ace crank and another with a 105 crank (I’m planning to upgrade it to a Ultegra one) and both have the same arm distance. Will I have any problem if I get the Dura Ace Stages PM and change it from one bike to the other because of the diferent crank set?
Thank’s a lot again and keep with your great reviews.
No issues. As you can see I mixed and matched in my review without a problem.
Wow, that was actualy a really quick reply!!
Tanks,
I forgot to ask on the last post,
What’s the real difference between the Dura Ace, Ultegra and 105 Stage arm?? Only the weight??
I had the same query and contacted shimano to verify the ultegra and dur-ace crank arms had exactly the same q factor and they responded that they did so there is no issue.
Ray, any updates on this? It seems many are having issues once the first battery dies (at well under the claimed 200 hours). I got 62 hours on mine, and ever decreasing hours on successive batteries. Stages support has been less than responsive, a dramatic difference from a year ago when they were very responsive.
Hmm, I haven’t heard anything from them, but I can reach out. I would note though that most happy users generally don’t post anything – and I know that Stages continues to pump out an astounding number of units. Thus, I suspect whatever may be the case isn’t widespread but rather something to do with specific units.
Great info! I’m buying a new bike with Dura Ace and wanted to find a way to keep the Dura Ace crank and sell my Quarc. You info really helped. Great Job! Steve
I recently purchased a Stages Ultegra 6800 PM, after reading many sites, all your reviews on dcrainmaker and watching Durianriders pro Stages Youtube videos. I love the concept of the idea, the ease or installation/battery maintenance, and swap ability – I’m happy with my purchase. Phenomenal effort wight he unbiased review – awesome work!
Do you think Stages would ever consider a core refund on the left crank arms everyones taking off they’re bikes. Or offering a retrofit service to keep the cost down to budget conscious bikers?
I have just started using a Stages Power Meter with a RFLKT+. Does anyone know if the 1s, 5s, 10s smoothing options are available as I believe would be using a Garmin?
I have a Stages power meter and a Garmin 500 head unit and do a substantial amount of indoor training.
While I’m indoors on the trainer I am unable to get speed, distance information to populate. Do I need the Garmin speed, cadence sensor mounted to the bike. When I purchased the Stages meter I was told at the shop that the Garmin unit would pick it up but that I would need to disable GPS on the head unit. I disabled GPS but still do not get speed or distance reading.
If this has been mentioned before or discussed previously I regret I was not able to find any reference to it.
Thanks
Clark Shaffer – Austin Texas
Unfortunately they were incorrect. Fortunately, it’s a relatively cheap fix. You’ll just need a simple speed sensor to get speed/distance indoors on a trainer. This is because the Stages has no way of knowing how fast you’re going (just power and cadence).
You’ve got a few options, though at the moment I like Garmin’s new magnet-less Speed sensor which affixes to your rear wheel. See details here: link to dcrainmaker.com
Thanks! Spending 3 or 4 hours indoors and uploading the data to show 678 feet traveled and no average speed is a bit aggravating.
Clark
Do you think we will see any new announcements at Interbike this year? Stages really hasn’t changed much in the past 2 years and was just wondering if you think they may surprise us with something new. Thanx
I suspect we’ll see many power meter related announcements and details between now and the end of Interbike.
I’m expecting to be surprised by a new SRAM Rival 22 crankarm that supports BB30 without an adaptor.
Do you have any opinions on shorter intervals (ie, 5-60 sec)? Do you think the Stages is accurate in this range? Two minutes is already starting to get into the long range for non-steady state efforts.
It would really depend on a person and whether or not there was a shift in balance between higher intensities and more normalized intensities. For me, I find that at short sprint intensities my balance is quite far off, so for me it wouldn’t work as well. Others might be different.
From a pure measurement standpoint there’s no issues with sprint efforts, it does that quite well. It’s just a case of how one’s balance might shift in those shorter sprint efforts.
Thanks
On one of your other post, you said that you’d put both 3s power avg & 30s power avg on your headset. How do you pace with those two values?
Do you try to put the 30s in your interval range and use the 3s to prevent extreme short bust? Or do you actually try to put the 3s average in range and just use the 30s avg as a reference as to how much power you r actually putting up?
Also, just wondering if stage power meters can be paired to two devices simultaneously? I’ve got mine paired to my garmin 500 but the Suunto Ambient 2 couldn’t find it.
Thanks
For me I use the 3s as more my ‘instant power’, and then the 30s as my actual ‘here’s what I’m basically doing’ power. So I’m kinda glancing at both.
For pairing to dual, it’s just like normal since the PM doesn’t know any better. What I suspect you’re running up against is that the Suunto Ambit series is notoriously finicky when it comes to pairing any ANT+ devices. In general you need to stick the watch right next to (like rubbing) the ANT+ sensor/accessory (Stages in this case) to get initial pairing. Once that’s done you can move it back to normal range.
I see. Thank you very much the timely reply.
Just tried it and the Suunto watch found the PM successfully. Now I can utilise the free charting functions on moveslink accounts. Well, If only my Suunto does not crash that often.
Another question regarding the manual calibration 15 minutes into a ride. Do I need to do it if I’ve already done a calibration when firing up the cycling computers? What’s the rational of doing the calibration 15 mins in? Is it mainly temperature consideration (stage PM compensates for temperature variation anyway)?
Thanks again for your help and the excellent review.
With Stages I’m seeing less of a reason to do a 15-min calibration check than other PM’s.
Thanks.
I’m surprised this hasn’t been talked about much more, but why is stages only offering a one year warranty? Doesn’t make much sense to be paying 150$ to get an extra year after already spending 700$+. Every other power meter manufacturer has an industry standard of 2 years. Stages really should just offer 2 years as standard as well.
That’s an excellent question. Anecdotal tales suggest few are buying the extended warranty, and Stages is standing behind the product, even past 1 year. I took the chance and didn’t get the extended warranty and out of two PMs, one had to be replaced, the other is still going fine (6 months in).
My view: if I had a problem the refused to cover after 1 year, I would let the world know about it. And, if a product is so unreliable an extended warranty is needed, I won’t buy the product at all.
Awesome work man. So useful to this potential customer. Much appreciated.
Help !!
I was seriously considering purchasing an Ultegra 6800 crank for my new madone 7. Series but the tales of battery problems really concerns me…is it worth getting one ?
Also, has anyone tried pairing these with a Bryton Rider 35 ?
Thanks.
Given the sheer volume of Stages PM’s being shipped (massive), I really think we’re probably in a case where only people with issues note it. If it was more widespread, I’d see far more comments (happy people don’t post).
That said, I did discuss it with them in person a few days ago. They noted that tracking down the earlier units with the door issue has been tough for them. They think they have them all out of the channel, but it’s trickier than they anticipated with global distribution.
They might get rid of all the negative posts on this thread if they published which serial number’s they have had problems with. Ray if you could push them to do this would be great.
I have an early one (first version did not work -second version seems fairly stable) but it is on a fair weather summer bike so I have been assuming it will likely fail at some point and thus have not bought another one for my winter bike.
To be clear, not all early ones. Rather, some specific batches where their door supplier went rouge and changed materials on them. Said supplier got Donald Trump’d.
Any way they could help us identify the door’s that had a problem? Does just replacing the door solve it or do we need to replace the whole unit?
I’ll ask at Interbike next week. Though, honestly, you’d only know once the unit showed up. And even in that case, Stages has been pretty good about swapping out for those with issues.
What crank arm from Stages compatible with indoor bike Schwinn IC Pro?
First you need to identify which bottom bracket you have (www.sportsmith.net/video-player.aspx?ID=a3e59e1b-6669-4036-b800-58cdce0641f0). Then you need to figure out if you can get a crank arm that fits that bottom bracket.
correct me if im wrong
i miss a part were the stages (crank power measuring ) or g3 wheel power measure is different
it like a car
you have engine HP and HP at the wheels
wheels being lower due to drive train power loss
this is the same with the bike
the crank is fairly consistent and the wheel has more variable power due to gear positions
this delta in power loss or gain will allways be there that doesnt make it worse or better power meter
Correct.
Do you expect Stages to simply update their line of products with new cranks & leave all existing ones the same, or do you think they will release all new versions with improved hardware for 2015? I’m looking to buy a bike in the next month & I figure I can probably negotiate a few bucks off a power meter if I buy it at the same time as the bike, but if new hardware is coming out late this year or early next year, it may be worth waiting on the power meter to get newer technology.
I know I could just wait a week & see what actually comes out, but who has time for that!
I suspect we’ll continue to simply see them expand the available crank options. Perhaps down the road in 2015 we’ll see something, but at this point they can pretty much just keep printing money with the current offerings.
Well gave the bike a “light” wash. Next day again. No stages. Flat battery, opened cover and internal tab broken.
Latest firmware update (v2.0.58) was released on Sunday.
v2.0.58 has been available for months now, it was definitely not released recently.
Yep. I realized my mistake a few days later when I saw that it was the information on the page that had been updated on the Sunday and not the version. Sorry about that.
Hi.
I have both the Stages and power2max power meters.
Today, I discovered during an interval ride trip that they measured peak watt differently. The Stages showed 20 % more then the power2max. The are located on two different bikes, so off cause one could argument that the riding position on the stages bikes is more efficient. Has any one other than me seen that?
If they were two different bikes on two different rides/bikes, then there’s unfortunately zero valid comparison you can make there. Would need to be on the same bike on the same ride recording at the same time.
at the moment i consider to buy a stages (shimano xt) for use on a mountainbike.
how about rain/water did they finally get the thing waterproof (battery-door/cover)?
did they change something other than the o-ring in actual models?
thanx
tom
I’ve had my Stages XT arm for about a month now. I’ve ridden it through water crossings in NC a couple of times, and have had no issues. It’s also been hosed off and bathed a couple of times with no adverse effects. I’m happy so far, and I continue to be happy with my Ultegra model as well. Two thumbs up from me.
Has anyone had issues pairing their stages with the wahoo fitness app on an iPhone 5 over bluetooth? I got mine yesterday, it works fine with the stages app and also works with trainerroad on my mac. I just cant get the wahoo fitness app to pick it up! I am sure I am doing something wrong.
I’m a long-term Stages user, and have had in total four replacements, all of which have started to drain batteries immediately after the original battery was replaced. I’ve actually been trouble free for about six months, but this weekend my Ultegra crank battery ran out, and the replacement had drained overnight.
The tab had snapped on the door, but I’m not convinced this is the issue – battery replacement seems to cause something to go haywire.
I’ve also just found that one of the tabs on the battery door on my Dura Ace crank has also snapped, so I’ve covered that with duct tape for now as I await a new one.
… puuuuh – this looks a bit like a never ending story. did you see any changes/updates they made in between?
Both power meters have performed flawlessly since about March (c5,000 miles). Then I replaced the Ultegra battery on Saturday and by Sunday morning it was flat.
i’m wonderind why they haven’t solved this ‘battery thing’ since more than a year. your patience is admirable …
There are obviously thousands of people who this hasn’t happened to (maybe they haven’t changed their batteries yet?).
andy – thanx a lot for your reply to my question. i wait buying a stages until they managed the problems. this summer the weather here in germany was annoying enough – so i don’t need a power-meter that sucks in addition …
have a good one
tom
Love the info on the review and from everyone. Just ordered my new bike and going with the Dura Ace 9000 crank w/ Stages. I used to run a Quarc Red Line power meter. Can’t wait to try it out.
I am in the market to buy simple left crank power meter like Stage for my MTB and later Road bike for Shimano (XT and 1050. Since I started reading this great review as well as comments, I am not impressed at all with the waterproofing of Stages sensitive electronics. Also has anyone tried to put clear silicon over the battery cover or edges of stages unit? I am asking in terms of not to be constantly replacing batteries of or in the worst case replacing cranks while they are still in warranty? Also what happens after short one year warranty? Does anybody have experience with customer service and replacement of Power Meter with Stages Europe?
Since my last post regarding the “seemingly growing” number of battery issues I’ve both replaced the battery, went riding in the rain and updated the firmware via my iPhone and blue tooth connection. In short, the unit continues to work just fine. When replacing the battery, had I not watched the video on the stages website I might have been inclined to pry or otherwise break off the tab. However, if done correctly, I don’t know how anyone could break the tab off. Th battery seat is designed to push the battery up and against the tab so as to create a good seal. Unless the o ring falls out or you damage the battery area, you should not have any subsequent performance issues.
I’ve replaced the battery in several of my units several times without damaging the tabs. And on every single occasion when the original battery is replaced the new one drains overnight.
The interesting experiment I have ongoing just now is a crank I took off my bike ready to return that had definitely had a tab break, mid-ride so definite water ingress, i left it in my desk for 5 days to thoroughly dry and four weeks later it’s still fine.
I don’t think they’ve cracked this yet as they’re all red seal, new door units.
I have been using a Stages 105 Power Meter since July without issue.
Last week, my Garmin reported that the battery in the power meter was low so I replaced it. In doing so I managed to break one of the tabs on the battery cover. The cover seemed to close ok, but the next day the battery was flat. I changed again and less than 24 hours later the battery was flat again. I suspect that water may have got in, has anyone out ther managed to successfully dry one of these units out or so I have to bite the bullet and ask for a replacement?
Thank you for the quick reply. I guess broken tabs on the battery doors are not much fun with Stages on rainy days!? Hope got new door from tgh Stages cycling.
My experience is that when I opened the door it was very easy to break the tabs, and once that happens the battery discharges quickly, maybe it’s not held securely and keeps resetting or something, Stages sent me a new door, and mine has been fine since that. I dread changing the battery again. So this is not scientific but I suspect discharge problems are due to broken door tabs, not water ingress.
So: handle your door with great care, and if you break a tab, get a replacement!
Thanks hhbiker! That at least sounds promising.
The tab that broke was the main one near to where you open the cover. This has a groove on it which pulls the door in tighter, so your theory does make sense.
I contacted stages straight away and a new door is being sent out to me.
Two questions: Does any use the Stages Rival crank arm and have you changed out the batteries?
I’m reading a great deal about all these battery issues but have not seen any with regard to the model crank arm I’m using. The unit is performing well but is beginning to show “0” from time to time in the power output window on the garmin 500.
I’m wondering if this is a precursor to the initial battery needing replacement and, if so, I’m trying to prepare myself for what appear to be substantial dependability issues subsequent to changing the battery.
Thanks
Clark
For those looking at/talking about battery issues, I’d heavily stress that the sheer volume of Stages sold out there significant outnumbers those having battery issues. Except, people never come back here to say they’re happy with a device – they always come back thinking it’s a forum where they can air issues and problems.
Which isn’t to say some people aren’t running into issues – it’s just that I think those are really few and far between compared to the number of units shipped. Assuming Stages has probably shipped between 50K and 100K units (easily), a handful of people here posting issues (many of them are the same people) isn’t cause for great alarm.
Ray, you are doing great customer support and testing service for Stages and other companies. Hope they gave you something good for exchange, when you bring them great new customers. Next time you will be in town you can stop by. Prague is a great city for all the testing you do and else. Cheers from Prague.
Actually I think your assumptions of a handful of people is wrong, me and my wife have both run into problems with both of our stages power meters and have already been through 5 replacements already. It would seem after talking to the UK distributors that this a major problem hence the numerous firmware updates surrounding battery life and the issues around the Bluetooth not turning off. This is all compounded by the unit not being sealed correctly.
It’s such a shame for what could be a great power meter.
If only they had better quality control and we’re not using their customers as design testers after spending hundreds of £££££ for all this hassle.
I’d agree that these problems are relatively widespread – I don’t personally know anyone in the UK who’s bought one who *hasn’t* had problems when they replace the battery – admittedly that’s only four peopke but it’s 100% of 4,mwhich have been bought over several months. If it was only a handful of rogue units it’s pretty remarkable that so many people I meet have bought dodgy ones.
I have had seven and every single one drains batteries as soon as i replace the battery. Occasionally one will work for a few weeks, but when that battery flattens it has always had the problem again.
I don’t know how widespread this battery-draining issue is but it took two replacements to finally resolve it. My coworker bought one several months ago. His, with exactly the same battery cover and the same red O-ring as mine, was working fine, except for this one occasion when he drove through a rain storm on the interstate with his bike on the roof rack and he discovered the battery had completely drained by the following day.
we have probably seen the equipment before.
Our consultants will use their experience from many sites to ensure that
critical to quality parameters are considered during this process.
We’ve seen what works and what definitely doesn’t.
equipment validation
… but what i’m wondering and what is statistically impossible if there really are only few with problems is that they had the same problem 2, 3, 4 or more times after receiving new ones on exchange (unless the users that complain are fakes) …
That is an interesting experience that you guys have with Stages PM. I am glad you clarified what I was asking about. Now I am convinced that Stages is indeed great power meter and that you have to be careful when you handling battery door. Perhaps not ride while raining with broken tabs. JK. Thanks guys.
Thanks for an amazing review as always. Please do you know if the issue of carbon crank arms is now a thing of the past? Looking to order this, but would like to make sure
No change there.
Stages now makes the FSA Carbon/Alloy 386 EVO Crankset PM. It includes all the bits of your drive train as well as your power meter on your left crank arm. Ray, any thoughts on whether the difference in material will effect the precision of the data?
link to stagescycling.com
Just wanted to chime in finally and say thank you for these extremely helpful reviews.
Also I just got off the phone with Stages and the rep said they just redesigned the battery covers which includes stronger plastics in response to the previous issues regarding battery drain (in the last month or so). The rep was very helpful and it sounds like they really stand behind their products.
Just purchased my Stages Ultegra 6800 power meter. First ride and my #’s were waaay low. Previous FTP test using virtual power from trainer road was 230w. I am a triathlete that averages 22-23mph on a 40k, but now have to struggle to hold 150-160w using the stages. Any thoughts?
Most turbo trainers are way too inaccurate in power readings to even be looking at them
Most electronic trainers, if calibrated about 10-15min in, are quite accurate. Meanwhile, comparing to Stages (which is one leg), is undoubtedly not going to be accurate.
That said, if using TrainerRoad’s Virtual Power function, then things are all over the map. Effectively you’re comparing two guesses. TR’s good if you have a method of calibrating/validating. But today they don’t yet have that for non-computerized trainers. So it fully depends on tire pressure being perfect with their power curves.
Meanwhile, Stages being left-only means it depends on you being balanced.
Stages replaced my defective 15 month old unit after the standard one year warranty was up. My battery cover was replaced last summer due to broken tabs, but I recently discovered that the interior tabs in the unit were also broken. The cover stayed on but was definitely not a water tight fit. They asked me to take pictures of the defective unit and when I took close-up pics of the interior and enlarged them on my computer I was able to see not only the broken tabs, but flaking and cracking of the interior plastic. So if you experienced broken tabs on the cover, then closely examine (with a magnifying glass) the interior to see that all is well or not.
But I can’t complain about their customer support. Next day shipping, brand new dura-ace stages crank. They even sent me a different crank length at my request. They do stand behind their product. I would buy from them again knowing I’m getting a quality power meter and great customer support.
By the way, I also have a power2max on another bike which shows that I’m 50/50 on my right/left leg power balance. I’m rarely off more than 3% on the balance during the ride and by the end of a ride it always averages to 50/50. So for me, the Stages works for me.
Garmin recommended to put the data recording from smart recording to 1 second interval. Now, I got a replacement power meter last week. The calibration of my new power meter reads approx 870>880 while the old “previous” power meter was reading calibrations values anywhere from 885>895. I do the same calibration every time. I leave the bike outdoors for 20mins before performing a calibration.
Now, it seems that the new power meter is reading watts approx 10% lower wattage than my old one.
My question is> Does changing the data recording from smart to 1 second have a drastic effect on the power meters wattage output? OR is the claim that stages make of +/-2 totally rubbish? is it more like +/-10%?
If anybody knows anything on this please help.
NOTE: i had smart recording enabled for my first power meter and now i have 1 second interval enable for my new power meter. I believe 1 second has made the power meter output a lot lower values.
The difference in calibration value shouldn’t make any difference, and the Garmins should automatically go to 1-second recording when there is a power meter connected.
You didn’t by any chance alter the zero-averaging setting? For power, the only setting that makes sense is to include zero values in the averaging (in my opinion). However, if you previously had it set to exclude zero values, then it would be expected to see a lower average wattage with zero values included.
On a related note, for cadence it is better (again, my opinion) to exclude zero values in the averaging.
Thanks for your reply Øyvind.
Yes i have include zero values in the averaging for power. I cannot understand why the power meter is reading so low in contrast to my previous one. The battery is also perfect.
Is the Stages working with the Polar V800 now ?
Thanks
It’s probably best to ask on the Polar V800 review post, but I don’t think anything has changed there yet.
Great review and analysis. I’m still trying to understand this stuff but this certainly helps.
I have just begun looking at power meters. I used to believe that it was a Pro only training tool/device. I was wrong. It’s a great fitness tool for all.
Ray, can you post a file of your Angeles Crest ride?
I’m so impressed that you rode that, I grew up next to that highway and it’s a favorite ride. I can’t believe you rode it on a rainy drizzly day in sunny LA. It’s a classic southern California ride. A tad dangerous with traffic though.
Excellent review!
Todd
I own a stages energy , powertap G3, and s Quarq else and my findings have my quarq and powertap dead even . When I run the stages at the same times as my powertap stages comes in at 10% higher . When riding my quarq my left right is dead even . I’ve sent files to stages and sent them my pm and they say it’s perfect but 10% is a large difference and they agree it is off compared to the other two by 10% . Plus I can tell its way off very easily.. Yet they will not refund me ..
The thing to keep in mind is that because Stages is left-only, it may indeed be actually 10% higher compared to the other two. That’s completely normal in a left-only scenario for some riders. That’s sorta the ‘risk’ to such a unit, that even if it’s measuring accurately, it won’t be giving you a complete picture of your power output.
Also, Stages measures power output at the crank arm whereas the PT measures power at the hub, post-drive train. Unless you have a 100% efficient drive-train (ie. absolutely no energy loss along the way), the Stages (or any crank, pedal or spindle based PM) will read higher than the PowerTap.
Hi Ray do you know if Stages are working for new cranks oprions in the near future? Hope to see something like an X1 mtb option..
Quick question (I guess this is as good a place for it as any):
Does the calibration generally change the output of the PM, or what the headunit displays and stores?
So if the calibration discovers that currently Watts are being measured as 10W too high, does – after calibration – 1) The PM report 10W lower, or b) the headunit subtract 10W from the value recieved from the PM?
Background: If headunit A doesn’t support calibration, can I calibrate with headunit B and then ride with A?
The “calibration” is just a command to the Stages telling it to read (and internally store) the current zero value. This is then presented on the head unit, but the head unit doesn’t use it for anything.
In other words, you can do a zero reset (“calibration”) with a different device (phone or other head unit) and then use it with a headunit that doesn’t support calibration.
Thanks, just the info i was looking for!
Can you connect both Bluetooth and ANT+ at the same time? Scenario: triathlon with Ambit3 reading Bluetooth and Edge 510 reading ANT+?
Yup, it always transmits dual concurrently.
I’ve had my Stages power meter for 5 months now and have had an opportunity to use it with a variety of devices. I originally bought the power meter because I typically log my rides on a phone in my pocket and the Bluetooth connectivity should allow me to add power to that. I also have a couple Garmin units but I don’t always have them on my bike. I have the newest firmware and all the newest software. I’m 5’8″, 150lbs, and have tried the Stages crank on both a carbon bike and an aluminum bike. So what have I found?
1. My Nexus 5 with BTLE cannot maintain a connection with the Stages meter if it’s in my pocket. With Strava, power will go to zero any time there’s a drop and with Wahoo, power (and cadence, which doesn’t work on Strava BTLE) will slowly drop or even hold the last known value until a reconnection. Staying seated increases the chance of maintaining a connection but even on a 40 minute seated climb the connection will drop a dozen times and might even stay dropped for 5 or 10 minutes, randomly. Before I updated to Android Lollipop (5.0x, now) that had a different Bluetooth radio software, I would reconnect much more quickly and I’ve found this documented on the web by developers. I’m not going to root my phone and change radios since it didn’t work well before, either.
2. My wife’s iPhone 5 had the exact same characteristics as my Nexus 5 over bluetooth.
3. A Garmin 500 (bike) or 310XT (watch) in my jersey pocket drops data a little less often than the phones but doesn’t work well enough to justify rooting my Nexus 5 to turn on the ANT+ radio (that’s already in hardware but only supported by third party).
4. My Nexus 5 mounted on the bars and either Garmin mounted on the bars works perfectly.
5. I’ve had very cordial and useful communications with Stages about this issue but have been told that it’s well understood that the crank power meter isn’t capable of working with devices in a jersey pocket (at least for some users). There was a mention that future firmware might help but the last two revisions have made no change.
It’s a decent power meter but having BTLE and planning to use your phone is only of value if you mount your phone to the bars or you’re much more translucent to radio waves than I am. Good luck!!
Well Firmware 2.0.76 is out and it apparently solves the battery draining problem that they said was always down to water ingress (even on my brother’s two cranks, neither of which was ever used outdoors). So after more than two years it seems they’ve decided to release an update that solves a problem that they’ve consistently denied exists.
We’ll see…
Andy, I got sent a second generation unit with the new firmware installed (warranty replacement). It’s guzzled 4 batteries in 8 days and only 2 hours of riding. I have the same firmware on an older DA9000 unit and the battery life is fine! I can’t figure it out at all!
So, I’ve had my Stages for 1.5 months and have to say that thus far, I haven’t had any issues. Now, this is my first PM and I am but a lowly non-racer who just enjoys riding the bike but I really can’t find anything to complain about…except one. A major reason for me looking at PM is that I started using a trainer (2 kids, ha!). Having the PM with TrainerRoad, Zwift, etc is so nice, gives me much more control and detailed information on my workouts. What’s a bit disappointing is the distance the Stages can actually send a signal. People have mentioned issues with having a unit/phone in the pocket and getting drops; I have to place my ANT+ USB device right next to the front wheel with an extension cable. If I just use the USB on the front of the PC forget it. Not sure why this is, maybe a battery thing (weaker signal, less power need?).
I can say that I originally was worried about water ingress and battery life but neither have cropped up. I have not tested right/left leg imbalance so I have no idea if I have a deviation but sometimes ignorance is bliss.
Matt, that’s pretty normal to need a USB extension cable for transmission. I needed one as well for my Garmin speed sensor and cadence sensor. So you’re not alone!
i have a stages power meter which head unit works best with as ive had some problems using my 910xt on my tri bike it losses any reading
Dura-Ace 7900 is currently on clear out at $449.
…on the Stages website.
Ray – need a hand mate. Had a stages 7900 since the release in the states (I’m a Aussie) had one shipped over. No issues since day dot. Had it swapped due to the internal tabs breaking. Also now have a stages 6800. Have you seen and proff there are differences in the readings between models? Setup on 2 bikes same wind trainer. Output I believe there is over a 30-40 watt difference. Fluid 2 trainer, connected to zwift – pushing a 55×14 at 100 cadence only reading 270-300 watts. This can’t be right.
Something odd for the other stages owners to test and verify. We had 3 units; sold two and kept one on the rain trainer after discovering this issue. We keep getting weird moments of zero reading from the units. It seemed really random. Turn out we could reproduce it on demand. Simply ride on your stages meter and switch to 100% pulling on the pedals. In all of our bikes the power reading went to zero and stayed there until we pushed on the pedals again. That was disappointing and it would make one really question the total accuracy of the meters. So whlie we still have one stages meter we are much happier with our replacement Power2Max type S meters. Curious if anyone else can reproduce. We’re not mashers we lean heavily towards spinning high rpms so it matter alot and the power numbers we collect now make a lot more sense and match our kickr results.
Can’t say I’ve had that issue with the zeroes. On climbs I definitely pull, don’t mash, and my Stages has been fine. I’ll continue to monitor, though, and post back any changes. That is interesting.
One issue I did have was 10 minutes into a ride the Pwr on my Garmin would not even show 0 just blank, indicating the Stages cut out or powered off. Each time I would open and close the battery door then it would be ok again, usually for the ride duration. I ended up sticking a small piece of cardboard to the inside of the door thinking maybe the battery was losing contact ever so lightly. Over the past month it has been fine, no drop outs or anything.
I’m going to be moving to the Powertap pedals this fall/winter, mainly to switch between bikes easily. Will be curious to see if any discrepancies show up; I like the Stages but have nothing to compare it to.
Bob, what do you mean by “switch to 100% pulling on the pedals”? How are you accomplishing this? If you are standing off the saddle, this could be a connectivity issue with the head unit. I had a unit that would drop power data when I stood on the bike due to a weak signal. In my case, replacing the unit was the only solution.
Taro,
Sorry let me clarify. Sit on the saddle, and only lift the pedals with your shoes by pulling up; don’t push down on them; down stroke is a dead leg doing nothing. We noticed doing drills on hill repeats as we were working on our upstrokes. Still not sure why the strain gauges don’t record anything. This was down with Rival Arms 165mm; I have no examples for other arms.
That is very interesting. I’ve never had this particular issue. I have ridden on the trainer concentrating on the pull stroke when I was recovering from a strained knee – can’t say it was 100% up stroke – but I found the stages consistent with my effort output. I found the Stages to be very sensitive (and accurate?) when I consciously change any effort on the left leg – pulling up or mashing down. Stages has been very good to me fixing issues like power drops and inconsistent data even after my warranty had passed. Despite some product production / software issues, they do stand behind their product.
I’m very encouraged to read that after all the software updated you would recommend the Stages power meter as much as other power meters. In my particular case I already own a Power2Max power meter, which I love, and I’m currently considering to purchase a Stages power meter for my new bike. However I’m a little bit struggling over performance of the Stages vs P2M and the additional investment. (Sorry if my comment is not purely related to Stages).
I have a P2M Type S power meter with Rotor 3D cranks and 50-34 chainrings on my old road bike.
My new bike came with a full Ultegra Di2 group and 52-36 chainrings. My plan was to swap the cranks and use the P2M on the new bike.
However now I’m concerned to use the Rotor 3D with P2M on the new bike due to the following
– Performance of non-Shimano cranks with Di2
– Different chain rings required Di2 adjustment, but I hate to mess with my new bike
Hence, my idea to install a Ultegra Stages PM instead and keep the new bike as much untouched as possible. However then I’m wondering how much different the performance is between Stages in P2M. From the P2M I know my left-right ratio is usually between 50% and 52% (left).
I too have a p2m on my main road bike. I know my left-right power ratio which is 49/51 when I’m going full gas, but generally 50/50 on all other efforts. Therefore, I’m satisfied with the stages to meet my needs for a pwr meter for my other bikes. Their customer support is excellent. I just had another issue and they sent me another replacement for a Stages that I originally purchased in 2013. And I did not purchase the extra accidental warranty. This is the third one they have replaced, but I’m fairly confident that they are correcting the problems I’ve had in the past, i.e. they will have a new design “in a matter of weeks” available. This recent replacement has a new housing design and I think they have addressed the problems they had with the old design (mainly to do with the battery cover and engagement latches). My Stages pm (I only have one) is so easily interchangeable, that if you want to use it on multiple bikes with compatible cranksets or don’t want to replace the crankset, this is the way to go.
As a follow up to answer your how Stages compare with P2M, I don’t know. I don’t think there are any problems with either as they are initially calibrated at production, and both are user calibrated, and compensate for temperature changes. I have not detected any power output readings that are off. But then again, I have no idea when my legs are on or off given a particular ride. I am very satisfied with my P2M. The P2M I installed last year and it has been install and forget it – it just works. But having said that, I will be buying another Stages soon (when the new housing is available) for my new cross bike.
I have 2 stages power meters and both have failed in the last month. They are less than 1 year old.
It starts with battery drainage, then dropping data, then complete failure of the strain gauges.
Once I get them back from warranty repair I am going to use them as paperweights or kitchen utensils.
I have 2 other meters from power tap(g3 hubs) which have performed flawlessly for 3 years.
I would not recommend anyone purchase a stages power meter.
They made a pretty big change back in September to address the battery drainage issue due to the waterproofing of the case. Details here: link to dcrainmaker.com
I’m not sure if the 2nd generation models will be any different in terms of reliability. Another one just quit working tonight. This will be the 5th replacement (and two have been for the 2nd gen models). And I don’t ever ride in the rain!
First one was for broken internal tabs for the battery door. Second was for data drops / weak signal. 3rd was for more broken tabs (brittle plastic). 4th was a 2nd generation model that had me believing that I should turn pro and ever increasing calibration numbers from 820 to 1004. The latest is also a 2nd generation that had a jump in calibration numbers and then just quit working.
These problems have nothing to do with how these power meters are used (I am meticulously careful with my cycling gear) – it is poor quality control. I love the Stages when they are working, but this is getting old…has been for awhile now.
I purchased a 2nd gen in September hoping for smooth sailing but aside from the obvious cosmetic change in the pod, my experience has been similar to troubled 1st gen users. With the 105 arm and a Garmin 510, I get one or two dropouts every 30 min or so which isn’t a big deal. But the main issue has been battery drainage. I’ve gone through 6 batteries now in 2 weeks… at less than a total of 5 hours ride time.
I’ve checked the cover, o-ring, and tried the paper technique while checking the tabs and I can’t figure it out. Batteries are dying in a couple of days. Folks at Stages have been pretty eager to help and resolve the issue, so I’m grateful for that. Waiting on new battery covers and o-rings now.
I have also had power drops and battery draining issues in separate units (generation 1). The power drop issue took 30 email exchanges to convince them that my unit was defective (that really tried my patience), but then the replacement worked perfectly… until the internal latch tabs broke when I was changing out the battery, and they actually convinced me to have it replaced. Should have kept that one since it worked and was only going to be used on the trainer. Now, I’m still looking for a replacement that works.
Just wanted to follow up on my post here. They ended up sending the o-rings and battery doors for the first generation by mistake, so I notified them immediately and they decided to next day a replacement arm instead for the hassle. Dropped the old arm in the postage paid box for return, mounted the replacement arm… zero problems since. I’m now at about two weeks with a handful of rides and battery reads full and haven’t had any problems with connection on the 510 or 520. Time will tell of course!
I’ve seen a smattering of people having to go through multiple power meters until they get one that works – here and at other forums. I for one will probably see a 5th replacement unless their support comes up with a miracle cure. I find it hard to believe that they can sustain this kind of business model unless they are taking big shortcuts on their production costs. Am I an exception? No, I was never the lucky one to win the lottery nor was I one to always get the short end of the straw. I’m beginning to sense from my experience with them over 2 years that the customer support folks are under pressure to “resolve” these issues with customers before issuing a replacement. I have had over 60 emails exchanges and multiple phone calls, and most of them has me defending myself that I am not doing something wrong with their product. I have tried my best in tolerating their patronizing tone. Their power meter cranks are installed in minutes, but imagine if you had to replace a hub power meter (or a crankset power meter with handpicked chain rings or devices that required a significant setup time) over and over. Would customers tolerate that? From my earlier comments on this forum, I fully supported them, but now I am about to turn the corner… if I haven’t yet.
I have had my 105 STAGES since August 2014. Until Sep 2015 it was fine, then it started dropping out on power but i noticed it was on rough bumpy ground only, the Edge 1000 would beep saying STAGES lost / detected. Inspecting the battery cover, i saw the tabs were broken, contacting STAGES, they sent me some new ones with new o rings immediately, no issue. Installed, still power dropped out. Inspecting again, i noticed one of the copper / gold plated three legs on the PCB battery terminal had broken off see picture, i contacted STAGES, they asked questions blah blah blah. After several emails, i took matters into my own hands, sticking a small 4mm square felt tape pad on the inside of the door in the hope it would stop what i had guess to be the CR2032 rattling around in there. Hey presto, no issues now since 1000km of riding. Gave up contacting STAGES since it works fine…….for now anyway. I am, have been and still am happy with it, it works now at least. Maybe worth a try for some?
I used the new version of the Stages PM today for my indoor roller ride. I use it with a Garmin 510 head unit. It appears that when I’m stopped, the power continues to be accounted for, thus bringing down the avg power and other metrics. What is the fix for this? Does mashing the stop button on the head unit resolve the problem? Or, setting the unit to not count zeros? Please advise, thank you.
You can turn off Zero Averaging for Power, and that’ll change that behavior.
I was sent a second generation unit as a replacement for an first generation which died after 8 months. The second generation unit has consumed 4 batteries in 8 days (and only 2 hours of riding)! It’s going back today!
The battery door does seem a lot more substantial on the new unit though.
I think I’m heading in the P1 direction though.
What would you suggest: Stages 105 or Rotor INpower 3D+?
Regards
M
I wish someone from Stages would come on here and explain exactly what is causing the rapid battery drainage problem even in second generation units.
I bought DA9000 Stages in April 2014 for my fair weather bike, which has been faultless apart from needing a new battery cover almost every time it needs a new battery.
Based on this experience I then bought an Ultegra 6800 unit for my wet / winter bike in February 2015. In November this year, while wiping the bike down after a ride, I noticed that the battery compartment had partially popped open. When I removed the door, sure enough two of the three tabs had spontaneously snapped off, and water had got in. The service from Stages UK distributor (Saddleback) & Merlin was excellent, and I had a new second generation unit within a week. I had high hopes for this in view of the new design. Unfortunately that was’t to be the case, and this unit consumed 4 batteries in 8 days with only a couple of hours of riding!
Previously this has been attributed to poorly fitting battery doors / water penetration, but that was supposedly fixed with the redesigned casing of the second generation units. Furthermore, this unit had never seen a drop of moisture.
The batteries were from 3 different reputable brands, & batteries from the same sources have been happily powering other devices including my other Stages first generation unit, so it’s obviously not the batteries at fault.
I wondered if the faulty unit was not “going to sleep” when not in use and hence consuming more power. So I would sneak up on it when the bike wasn’t in use, with the Stages app running on my iPhone to see if it was broadcasting when it should be asleep, but that certainly wasn’t the case.
I can only conclude that there is some fundamental flaw in the electronics, which Stages clearly still don’t have a handle, on as my replacement second generation unit was afflicted with exactly the same fault some first generation users described years ago. This is such a shame. For me it was almost the ideal power meter, as I wanted to stick with my Shimano crank / chainrings / SPD-SL pedals and Mavic Exalith wheels. Plus, having the device as part of a component with no moving parts (the left hand crank) made me feel it should be more robust than some of the alternatives.
Merlin kindly gave me a full refund when I returned the second generation unit. I’m now thinking about switching over to Powertap P1 pedals, but the less stable nature of the xpedo pedal / cleat interface makes me want to stick with SPD-SL.
If I though Stages had any kind of handle on what the problem is I might be inclined to give them a third chance!
Hi ! first – thanks for amazing site, first post, but I read it all the time !! Can’t find an answer: would a Dura-ace stage crank on an Ultegra set bike ? is there an issue with Dura-ace left and ultegra right ? thx !
I initially was posting under the Garmin 520 section but feel now its more appropriate to post here, under Stages PM. I purchased the new carbon Stages crank for Red 22 BB30 but was having power drop out problems with my Garmin Edge 500. I was using the SRAM Garmin mount (in front of bar) like I always used pre-power meter. My buddy got the Edge 520 with his Stages PM and it worked fine, so I decided to try it. My Edge 520 that I got was also having drop out problems, in fact much worse than the 500, so I decided to do some rides with the 500 and 520 both paired to the Stages. Turns out which ever head unit was in the “out front” mount (in front of bar) would drop out frequently and which ever was in the stem mount holder never dropped out. So is the handle bar blocking the Signal? Is the Stages signal a weaker ANT signal than other power meters that rarely, if ever drop out? It seems that its a Stages problem as opposed to Garmin but Stages refuses to admit that, putting the blame on Garmin. Yes, I could just use the stem mount and not have many, if any drop outs. But why wouldn’t this be something that should be addressed by Stages if so many users of Stages have this problem? Thoughts Ray, or anyone? Pretty frustrating!
I’ve been through a few defective Stages PMs. One was a unit that would constantly drop the signal. I did multiple tests accounting for interference from other devices, placement of my garmins, battery changes, etc… The only way to eliminate drops was to mount the garmin on my seat post. And the only thing that resolved the problem was a replacement unit. Once I got the replacement – no problems. Dealing with Stages was a huge headache. They would not admit that the unit would have that kind of defect. I’ve said this before, they have poor quality control.
Its weird because I’ve heard so many good stories about Stages customer service too. So far thats not the case for me. They are basically blaming Garmin and not taking the blame themselves. I tried 4 different Garmins so far and they ALL drop out! 2 Gamins are mine, one from buddy who has a Pioneer PM, and one from a buddy who has P1’s. Their power meters NEVER drop out with the 2 Garmins I tried. You should not have to mount it to your seatpost, top tube or whatever. If a head unit is 3 feet away and all that “slightly” blocks it is a narrow handlebar, theres something wrong! I have a feeling Stages is going to string me along on this for a while until after my warranty is up. They refuse to send me a new one…so far.
They will have you jump through hoops but being under warranty they will have you send it back and you will get a replacement.
I had a similar issue with a G2 unit. After a couple of weeks working correctly, I started to get major connectivity problems on ANT + – basically the unit had to be within 50 cm to pick up properly. Interestingly the BLE signal was fine.
Stages replaced the unit and it now works fine however the Ant+ signal is WAY weaker than the BLE signal, and also much weaker than the signal from my Powertap G3 hub, so the signal strength may still cause issues.
I have found the support to be very good, but I also have the impression that they may still have a couple of design and or quality issues even with the G2 units.
I couldn’t agree more. After reading many forums and talking to friends with stages and other PM’s, it seems obvious that the stages ant signal is weaker than most other PM signals. It also seems some stages have stronger signals than others. I rode with a buddy yesterday with stages and he held my Garmin and I held his and we started very slowly riding apart from each other. This was for me to let him know when his dropped out and vice versa. My power dropped out around 5′ and his didn’t drop out until he was about 20′ from me. We did this 4 times and every time the same thing. Its simple, my stages is putting out a weak signal, but so far stages won’t budge. For right now, I’m not liking stages customer service very much!
Hi! The same thing happens to me. I’m using Stages (2nd generation) with Garmin Edge 500 and have constant connection drop outs when the Edge is on the barfly mount (insomuch that Stages will go to the “sleep” mode).
When the Edge is on the stem it seems the handlebar is not blocking the way to ANT+ signal and the drop outs occur but not so often. I also blame the weak signal of the transmitter on the Stages.
I’ve tried replacing battery, manually pairing the Stages with the Edge, removing and unpairing all other ANT+ devices, hard-resetting the Edge, – nothing helped.
The only case when the connection is reliable is when I’m on my turbo trainer and the ANT stick (connected via usb extension cable) is placed on the floor 30cm from the crankarm.
Hi Konstantin – Yes it was really annoying for me. Since my post Stages finally (took a long time!) sent me a new crank. I used it several times with my Edge 520 on the bar mount and it has been working great. I even had my friend hold it while we were riding and slowly rode away from him until it dropped out, which was approx. 5 meters away…not too bad. My last PM would drop out at about 1 1/2 – 2 meters. The only thing I’m concerned with now is that during a mountain trip a couple days ago (I brought my older Edge 500 because I was going to do some mtn biking as well) it dropped out several times. Not sure if this was due to using the older 500, or being in the mountains with dense forests or…? Im back home now and will be testing it out again with my 520. Fingers are crossed!
But to me there is no question that there is a weak signal with Stages PM in many cases!
Opened the support ticket – will see what they think on the issue.
Have you by chance tried Bluetooth connection on the 520 instead of ant+? I wonder if it improves the situation significantly
No I have not tried bluetooth. Good luck with Stages and keep on them!
I’ve had my Stages Gen2 for about 5 weeks now and it is terrible. Using the .fit file repair tool I’ve found that when mounted out front the reception between my head unit and the Stages is about 37% which leads to CONSTANT drop outs, so bad the PM is almost unuseable.
Stem mounted resolves the issue but this is not acceptable to me.
Which head unit?
Edge 520.
Same here, I just purchased a stages PM 2nd gen and I’m having lots of drop outs….
My head unit is a garmin 1000, and analysing with fit file repair, when mounted out front the reception between my head unit and the Stages is about 30-35%, which means in practical terms 2-3 dropouts per minute, unusable.
When mounted on the stem, the reception improves a lot, up to 73-77%, but this is not good enough, as you still get 5-10 dropouts per hour, better, but still annoying and not good enough to get the right power averages (and not good, since I like more the out front mount)
Any advise? should I push for a replacement? the PM is just 2 weeks old
I’ve returned mine to the retailer and they are sending out a replacement.
Got the answer from Stages support then (first they asked me to provide the photos of the power meter and head-unit location on a bike):
“…Looking at those photos your power meter is in really good condition, so I do think the dropout issue you have been seeing is more likely related to the location of your 500.
We have seen a similar issue with the 520, although potentially caused by a different issue with the new 520 ANT+ chip stack. The 510/810 have been the most reliable in our experience, but the former has since been discontinued by Garmin…
…For the time being, having the 500 mounted on the stem, or looking into the 810 option from Garmin would be the course of action I would recommend. Because the stem mount does not show the same activity, I think the issue more likely lies with the orientation of the receiver there, rather than the power meter itself…”
I consider switching to 510 atm
As you may have read I have had many issues with my Stages 2nd gen/Garmin 520 set up. I’m still not exactly sure who’s fault it is…possibly both. I see Konstantin your remark from Garmin about the 520 ANT+ chip stack, which doesn’t surprise me. Though I also feel the Stages puts out a bit weaker signal than some other companies for whatever reason. And BTW I used my buddies Garmin 810 on a few rides along side my 520, while alternating them back and forth from stem to out front mount, and the 810 never dropped out while my 520 had its normal dropouts, so…
Also, I am on my 3rd Garmin 520 as well as my 3rd Stages 2nd gen (though the 3rd time I sent back the crank arm and they just replaced the internals). Knock on wood and I’m happy to say I have not seen one drop out in my 10 or so rides yet. Man I hope I just didn’t jinx myself though!!
Has anyone else had an issue when trying to update the firmware. Iphone app is connected to the PM yet when trying to update the firmware the screen shows status at 0% and then just hangs at that percentage and does not actually complete any update. Go back to the home screen and the app is still connected to the PM so no issues there. Brand new battery in the PM and phone fully charged. Extremely annoying.
Very in depth review, as always i enjoyed very much.
I wanted to install the stages powermeter (dura ace on my ultegra crank arm). However that was not possible since the powermeter comes into contact with my ultegra break, which sits under the bike. Anybody had the same problem and maybe a solution?
You might want to reach out to Stages to see if they have specific frame recommendations. Most PM companies can tell you which exact unit will work. Unfortunately, if it’s hitting, there’s very little you’ll be able to do aside from swapping out for a different unit (if that).
I updated my firmware a week ago (on Tuesday 19th April) to version v2.0.79 and I seem to have issues with batteries draining very quickly.
The first battery that I replaced at the same time that I updated last a week (180 miles) and the battery that I put in yesterday was dead this morning.
Well, I say dead but I don’t actually know if it was. The power meter refused to wake up and connect to my garmin. When I put a new battery in in woke up and connected straight away.
I am following thsi link for a while now, i’d like to post my thoughts and i think my solution. My Stages 105 i have had now for 2 years, about a year ago it also started playing up intermitently loosing / cutting power readings so i contacted Stages who sent me x2 new covers and new red o’rings. Fitted them, all was ok for about 50km then started again. Taking a closer look, i saw the x3 gold plated battery prongs on teh pcbs, one was missing and they looked flattened so i bent one up then on the inside of the battery cover fitted a small square of thin felt tape. Now ive covered at least 3000km or more, no issues! I believe the intermitent cutting out is caused by the PCB prongs and the battery rattling around inside the battery cover. Give it a try, it might just work for you but i know we shouldnt be doing this but worht a go and at least the tape you can remove if you wish to return it. Good luck.
Thorough test, thanks! Does Stages power meter also measure the upstroke (of the left leg, I suppose, and then double it)? Does it perhaps measure the entire stroke/rotation of the left leg?
Does anyone know the effect of not zeroing a Stages before a ride? Does it result in higher or lower power numbers? If there is little to no effect then i’ll stop doing it for every ride!
Hi Lewis – I always calibrate before every ride and try to get the calibration around 900. I have found straying more than 7 (calibrate between 893-907) in either direction results in drastically higher or lower power numbers. I can usually tell by my effort and HR where I should be on power and have found that calibration range to be most accurate for me. Sometimes a pain getting it there when you are in a hurry to ride but worth it for the data consistency.
There is no such thing as “trying to get the calibration value within some range”. Calibration is done with the arm vertical, and that’s it. You get the value you get, and it will vary a little due to temperature changes and it can also shift a little as the meter is ageing.
As long as the value is between 840 and 940, and hasn’t jumped drastically since the last calibration, you should be good to go. Here’s what Stages says:
link to support.stagescycling.com
I always do a calibration (which is not really a calibration, in the true sense of the word) before each ride, because even if it might not be necessary, it takes literally just 10-15 seconds of my time.
I zero/calibrate my Stages PM before 95% of my rides, but sometimes on a commute home i don’t bother. I have never seen any numbers or load scores that seem out of the ordinary. I don’t have any reason to believe that it makes a huge difference to the power data.
I am yet to find any information out there that can tell me what is the actual effect on the power data. I would love to know. Might be a question for the Stages support team?
Zero offsets in the cases of Stages are mostly useful for identifying when something is going horribly wrong. Stages automatically compensates for temperature differences, so the zero offset is more of a formality and quick validation than anything else in their case.
That said, it’s useful to do prior to a ride, as if it comes back with a wonky result, you’ll know then rather than during the ride or afterwards.
Any news on availability and pricing for their dual sided version?
thanks
Joel
No near-term plans there from what they’re saying. I wouldn’t expect to see anything till at least next year on that front.
My unit is just over a year old, well more like 18 months now and i’m having huge issues with it that started back in July.
It had worked faultlessly until that point, fit and forget. On that ride, all was normal and then my head unit (Edge810) stopped receiving cadence and power data. Odd, i thought, but i suspected a battery seeing as i hadn’t ever replaced it.
Went to change it and the door just came away in my hand, the lugs were broken. Spoke to Stages and they sent me out a couple of doors and new seals.
Since then however, i’m having huge problems connecting to the unit. To the point where i now just give up and ride. My Edge just can’t find the Stages. Sometimes it will find it if i hold it right next to it, but it doesn’t even seem to do that anymore.
I did a ride today and paired my Forerunner 920 with the Stages as well last week (as a back up). Neither unit could connect this morning so i just went for a ride. During the ride, when i looked back at the data, the 920 was receiving data from the Stages for a little bit. Then it dropped off and then came back again. I also got a ‘Power Meter Low Battery’ warning at the end of my ride. The battery was brand new this morning (in an attempt to get a connection).
Any thoughts as it’s become a real pain. 75% of my training is power based and i’m on the verge of going and buying an alternative solution.
Thanks
Probably want to call their support.
I’m having the same issue with mine to the point I’m ready to just buy a new unit as well. I called Stages and they sent me a new door and seals just like you. I got it to work but continued to have the same issues with the cadence and power readings continuing dropping out. I called them back and they basically said they’ve had issues with Garmin products and the unit needs to be as close to the Garmin as possible. I have the 920xt as well and I expressed my disbelief that they would create a product that is essentially incompatible with the leading multi sport watch brand in the market. I’m paraphrasing here but tough luck was essentially the response I got. I understand they are the “value” version in the power meter market but $750 is not a drop in the bucket. Extremely frustrating.
Anyone have any suggestions?
Thanks
Marco
In “studies of how people peddle:” you wrote “Keep in mind that it’s last year that we finally got a left/right power meter that works outdoors”. I realize that this article is over three years old now, but I wanted to point out that the Polar Power Output sensor was available in 2001. It did in fact offer left/right pedaling analysis in the form of l/r percentage and circular distribution (they called it ‘pedaling index’). It wasn’t a real power reading but I suppose one could have extrapolated power. FWIW, comparisons against a computrainer were pretty good, never varying more than 5% for peak and interval measurement, and pretty damned close for average ride readings.
I used it for about 5 years starting in 2005, until I got hit from behind on a group ride which tore off the chain speed sensor that attaches to the lower jockey wheel. The thing was a total PIA to set up – both mechanically and programming – and I had an issue with the battery only lasting about a week. While futzing with to see why the battery kept dying, I discovered the 3 pin connector inside the handle bar mount had the power and return pins ever-so-slightly shorted. After I fixed that I quite literally had trouble-free seasons with it. until the crash.
BTW – this article is great. I’m an EE, love the scientific approach and report.
Hey, so question on your comparison plots: from the titles, one would assume that you are showing Quark-Stages, Powertap-Stages and Powertap-Quark (lets use these three… and those are minus signs). When I look at those I see a pretty interesting trend: Q-S shows that the Quark is giving you 10W more power during your actual power on intervals (likely due to the fact that when your left leg fatigues and you subconsciously switch, it reads it), P-S shows the opposite, which again makes sense as the Powertap is at the end of the powertrain, so you’re subtracting off higher watts from the one legged “crank horsepower” if you will, which causes the negative numbers, and the final P-Q which shows a net-zero effect. What I’d like to know is, what is that effective “left-leggedness”? is there a correction factor that could be calculated per-person… for instance, riding on rollers with a powertap and a stages, I could develop a correction curve, which would in effect map out that fatigue… but that would be different on any given day, and any given level of fatigue or alertness (extra strong coffee)…. so really… it’s not as accurate a power meter… the variance shown there is substantial, even if your NP’s show to be within an acceptable tolerance, your NP per interval is not (by the looks of things anyhow…).
I only bring this up as I have been using stages for training myself for a couple seasons, and have been very irritated by the one legged situation (as all one legged power meters would be). Outside I find that the power meter performs quite well, though this likely due to the lack of control of variation and continuous variation at that. Indoors with set intervals, I find that the power is quite mis-representing and under-represents your output due to all of the controlled variables and being able to mentally focus on which leg puts out more power…
Anyway, I haven’t read your previous version and I noticed the preamble on “you’re doing it wrong” with regards to pedal efficiency and bias… just curious as to what your thoughts were on those 10-20 watt variances. Otherwise, as always you have an exceptional blog!
Thanks
Great review, Ray!
You´ll find also some testing and reviews on link to powermetershop.com
Hi Ray
I know that this is a very old post now but I thought that this was probably the best place to ask you a question.
I have an Edge 1000, several Virb cameras and a stages power meter. I have a Virb on my handlebars so that I can see it’s display.
Fairly often when I look down at my Edge the power reading is nothing (– as opposed to 0) – this can last several seconds, possibly up to around 10 – 15. This is when I am pedaling and is not after I have just re-started so there should be power displayed and sure enough on the Virb screen I can see power.
I thought that maybe the Edge was dropping out and not getting these values so for one ride I compared the data from the Edge to data from the Virb by uploading them both to Strava. I was expecting the kilojoules of the edge to be lower due to it’s drop outs but the values were basically the same and in fact the edge was ever so slightly higher.
It seems to me that for some reason the Edge is receiving data but not displaying it. The field I use is instant power, no averaging.
I suspected that this was a problem with the Edge so I paid for a replacement from Garmin outside of my warranty period but this had no effect on the issue.
I saw that on another post you mentioned that drop outs from Stages were not unheard of so I thought it was worth asking.
Do you have any theories?
Many thanks
That’s definitely odd. Usually the drops are drops – meaning, they definitely show up in the file. One thing to double-check though is whether Strava or GC is ‘faking’ the missing data. GC does this by just pretending they weren’t drops and marking them null. I don’t remember off-hand if Strava does. You could use the DCR Analyzer to double-check too.*
If you want, shoot me two files and I’d be happy to do a quick overlay for you to see what the Analyzer shows. I know you’ve been a longtime DCR Supporter – I appreciate it! Just ray at the domain.
Also, I presume you’ve updated your Stages power meter firmware too. There was an update last April that helps out a fair bit here.
*http://www.dcrainmaker.com/analyzer
Hi Ray, did you see the email I sent you with my day files in?
Many thanks for the offer of help, much appreciated.
Within the last couple months my Garmin 520 has also been unable to get good data from my stages power meter. I had very few issues until recently. I sent my power meter back and they couldn’t find any issues with it. I find a ton of zeroes when I’m pedaling. Garmin claims it’s the low ant+ broadcast from the stages meter. I feel like maybe Garmin changed their OS and this has affected my data immensely.
Thank you for the review. Most probably, between pioneer-4iiii and stage left only options, I will go for Stages.
I bought a stages power meter way back in 2014 but as I have recently crashed my bike and got an insurance pay out I am moving to a Quark.
Stages support have been brilliant. Despite only paying for a power meter in 2014 I think I have probably had about 5 brand new power meters from them for all 3 generations.
The first generation suffered from water issues. I was sent new doors and seals but eventually they replaced it with a Gen 2.
I can’t remember what issues the Gen 2 units I had were. Possibly water or possibly accuracy…
The Gen 3 unit had very odd accuracy issues and was replaced when I had it for only a few months.
As I said I am very happy with the customer support but it seems that this far into a product’s life they should have ironed out these recurring issues.
Now that I have an opportunity to move to something else I hope that the Quark will be as accurate and resilient as Ray implies it is.
the best customer service is making products that don’t require customer service. IME stages fails miserably on that metric. Between my road and MTB, I have had 3 devices on one and 2 on the other. They seem to finally have gotten it right. Their early product claims were pretty much fictional. Stuff like 200 hours of battery life when I was seeing maybe 30.
I purchased the original gen 1. It developed the well known crack in the plastic housing as well as the battery door failing initially.
Whilst the customer service team are prompt and polite there will be a lot of people like myself whom committed to the first gen paying a lot more than they retail now for a product not fit for he market.
Unfortunately out of warranty in the UK you just get a discount of 30% on a new unit (gen 3).
In my case it never saw rain with the bike stored indoors and only a 1000 miles done on the bike.
Not what I’d call value for money. So if i purchased the new gen 3 my total outlay for a left sided power meter only would be over £1000!
If and when I do get another power meter thinking of 4iii as have heard better things and it’s cheaper than the stages even with the discount!
If your looking at a power meter I would recommend looking at known faults and issues with all companies. As mine was a gen 1 this wasn’t available at the time of purchase.
I had similar experiences with a gen 1 on my mtb and another on my cross bike. Between the two, I am on my 4th and 5th pm from stages at this point. Stages 1st gen products have been without a doubt the most troublesome cycling product I’ve ever purchased. Having to pay to for upgrades to newer models when the older ones were clearly not ready for the release just adds insult.
Really appreciate your thorough testing and reviewing of equipment. As a Stages 3 power meter user, this update is gratifying and helpful as I adapt to the power meter world. So, thank you.
Buy a Stages XT Gen 2 left crank and make a Lama Test Lab like GPlama does and I get a 20w-25w difference all the workout. The Stages as lower watts than my Tacx Flux S.
Is this normal?
The calibration value is only 869